4. Structural Sources in Training: Synchronization & Control Conflicts
4.1 Synchronization and Interconnect Effects
The most deceptive form of loss is Ghost Compute (Type A). This represents active compute cycles that consume power and execution resources but fail to advance the observable state of the model. These are primarily Synchronization-Induced Losses that occur when hardware is engaged but effectively stuck in a waiting room.
- The Llama 3 Synchronization Barrier: During the training of Meta's Llama 3, synchronization and collective communication patterns occupied between 20% and 30% of total iteration time[2].
- Secondary Loss via Checkpointing: Beyond communication, secondary structural tasks such as checkpointing accounted for 2.1% of total training time alone[2], further eroding the compute budget.
- The Databricks Scaling Inefficiency: Scaling Llama2-70B from four to eight GPUs yielded only a 0.7× latency improvement instead of the idealized 0.5× expectation, with the deviation attributable entirely to communication overhead[4].
- Topology-Induced Fragmentation: A system may report 20% free capacity while being unable to satisfy allocation requests because the remaining accelerators are distributed across non-adjacent racks or incompatible NVLink domains[5].
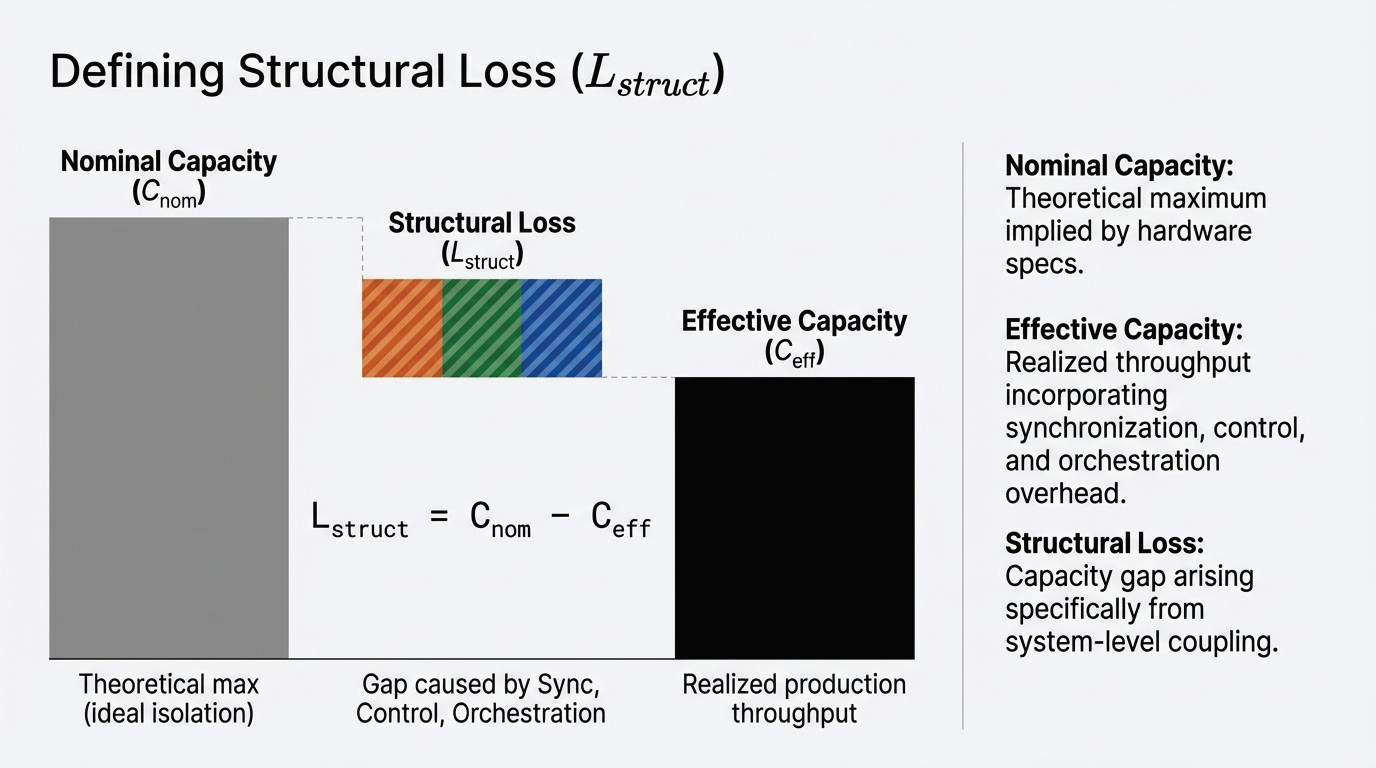
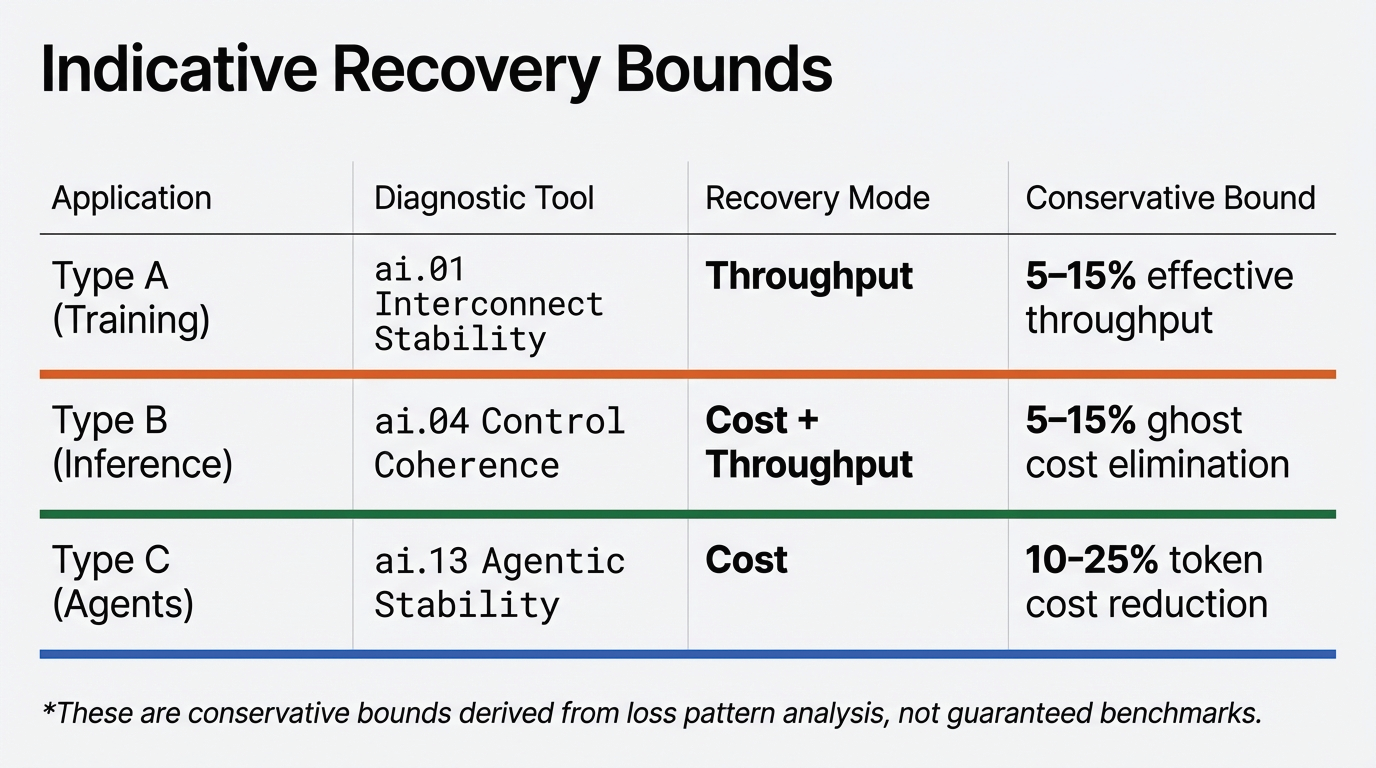
This is diagnosed through ai.01 Interconnect Stability Control, which analyzes gradient flow topology and interconnect stress patterns to recover 5–15% effective throughput.
4.2 Runtime Control Layer Conflicts
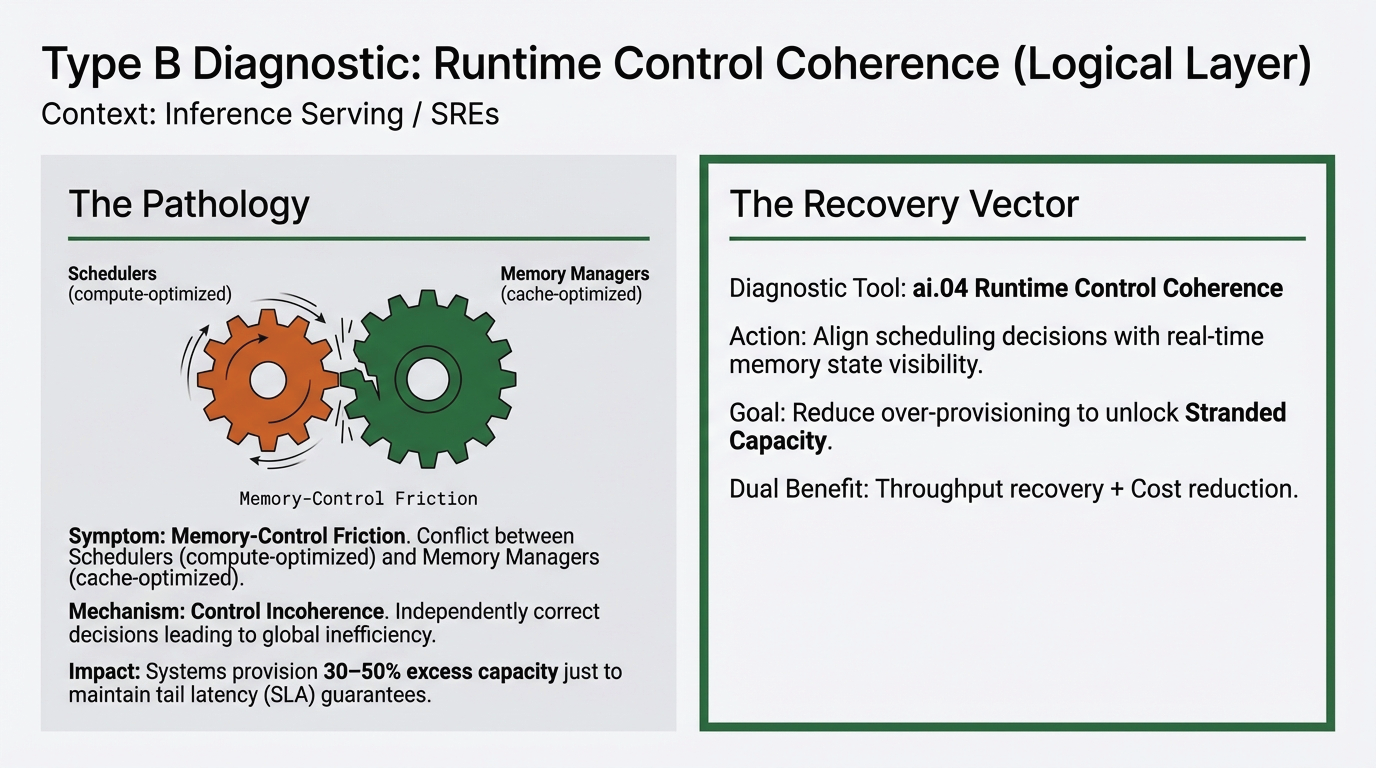
Stranded Capacity (Type B) arises from Memory-Control Friction, where autonomous layers of the stack operate at cross-purposes. This is a failure of control coherence: the scheduler and the memory manager making "locally rational" decisions that result in "globally inefficient" outcomes.
A cluster scheduler may observe low compute utilization and respond by injecting additional load, while the serving engine operates in a memory-bound regime due to KV-cache fragmentation or paging constraints. From the scheduler's perspective, unused compute represents opportunity; from the serving engine's perspective, memory bandwidth is already saturated. Both components behave as designed, yet their interaction limits effective throughput.
Meta's ads inference clusters were intentionally operated at only 30–50% utilization to preserve tail latency margins[3]. This capacity is functional and powered, yet structurally unreachable due to the lack of visibility between the scheduling tier and real-time resource saturation.
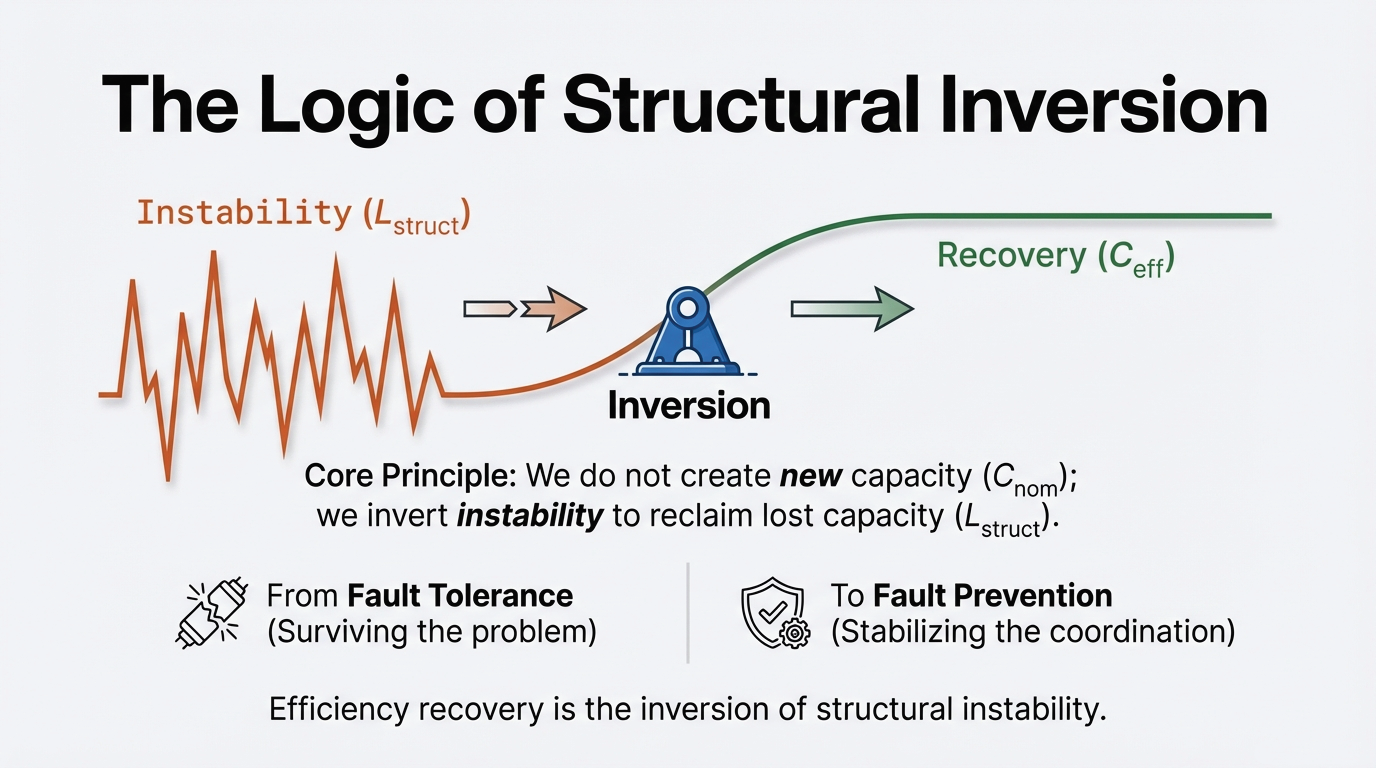
Alibaba's Aegaeon system provides a blueprint for recovery. By implementing software-defined pooling and token-level scheduling across heterogeneous accelerators, the system reduced the number of GPUs required for a fixed workload by 82%[4]. This was not a hardware breakthrough; it was the recovery of stranded capacity through structural orchestration.
This phenomenon is analyzed in depth in ai.04 Runtime Control Coherence, showing how aligning scheduling decisions with real-time memory state visibility can unlock 5–15% ghost cost elimination.