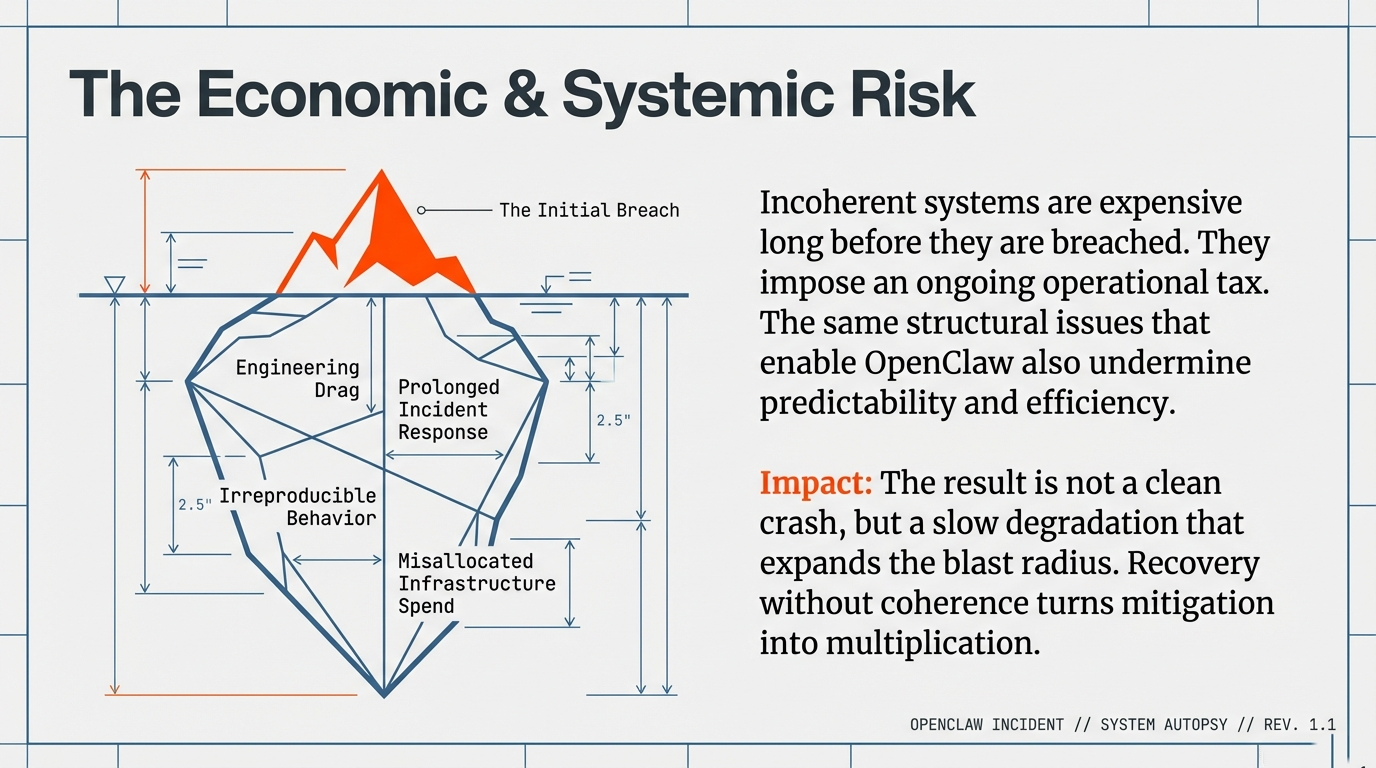
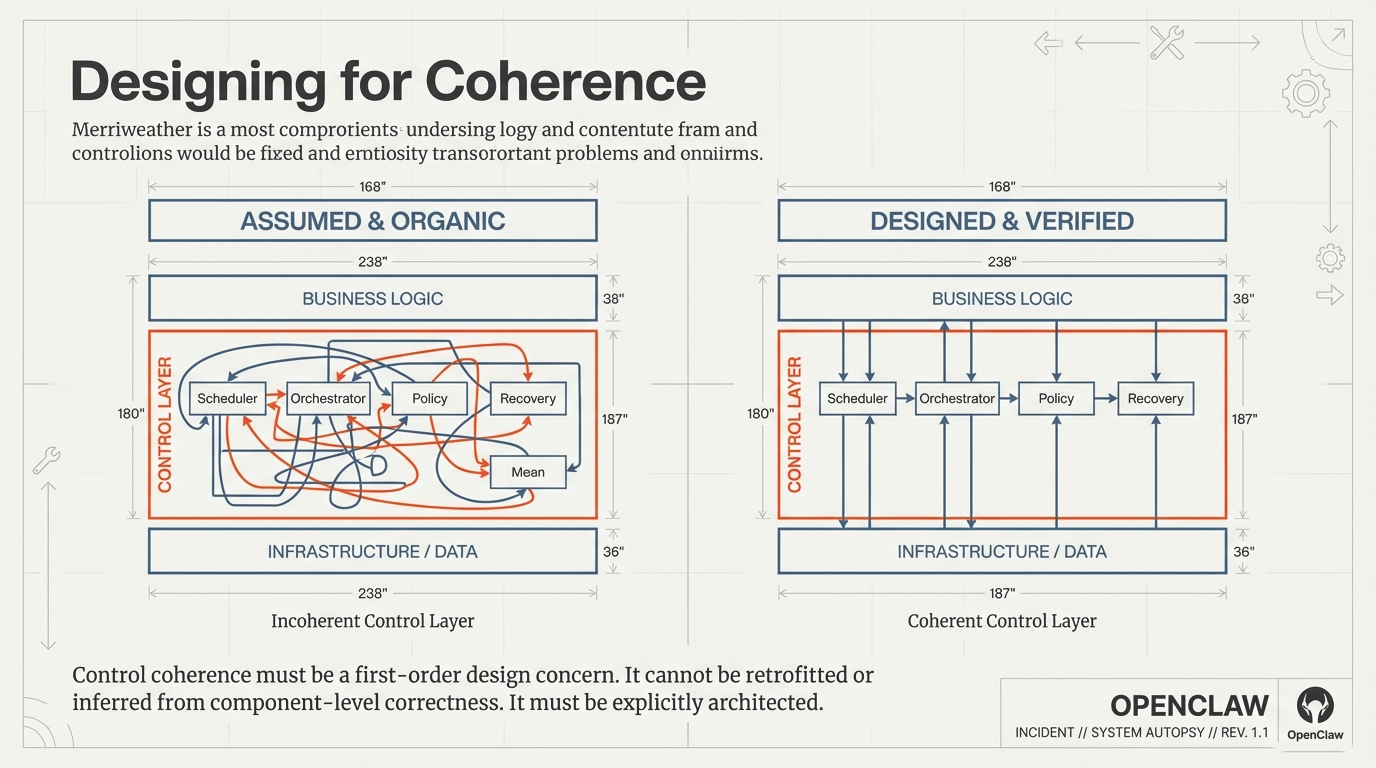
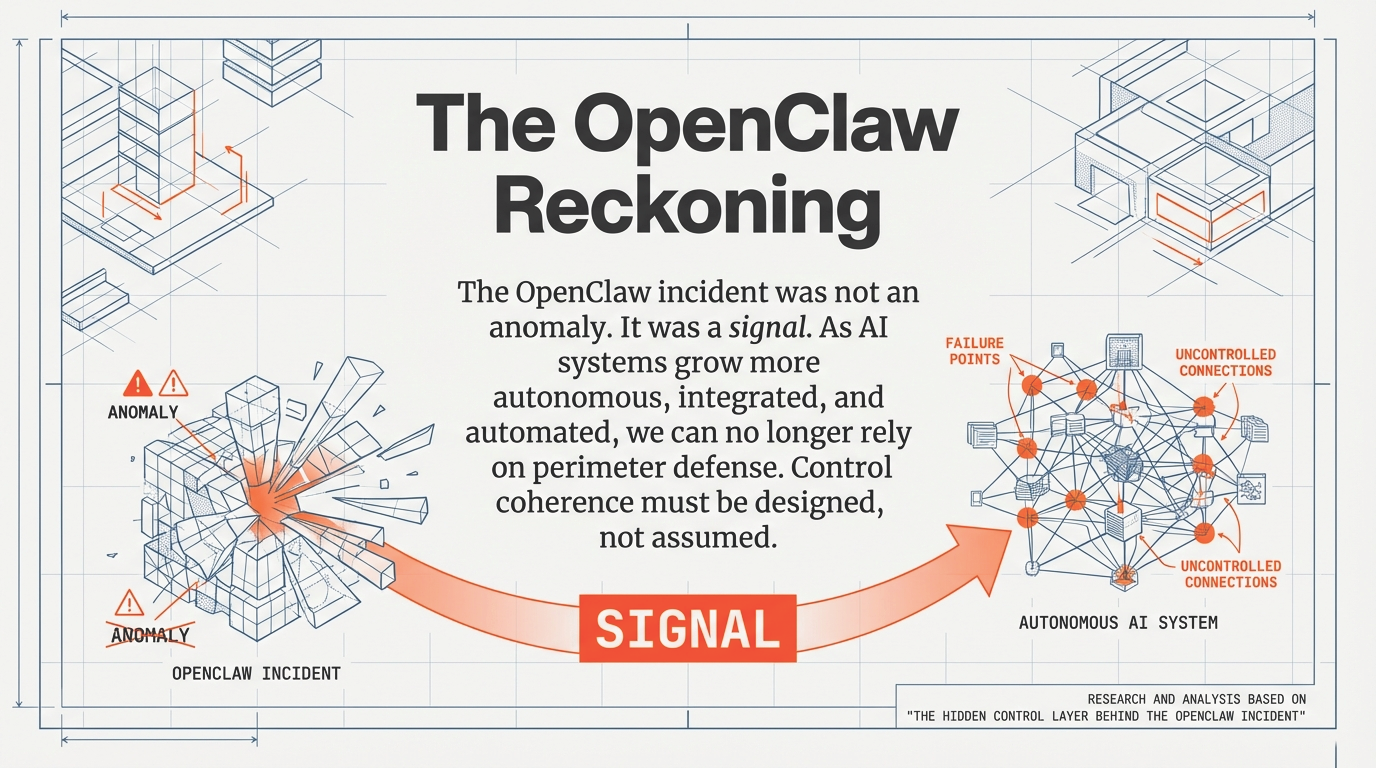
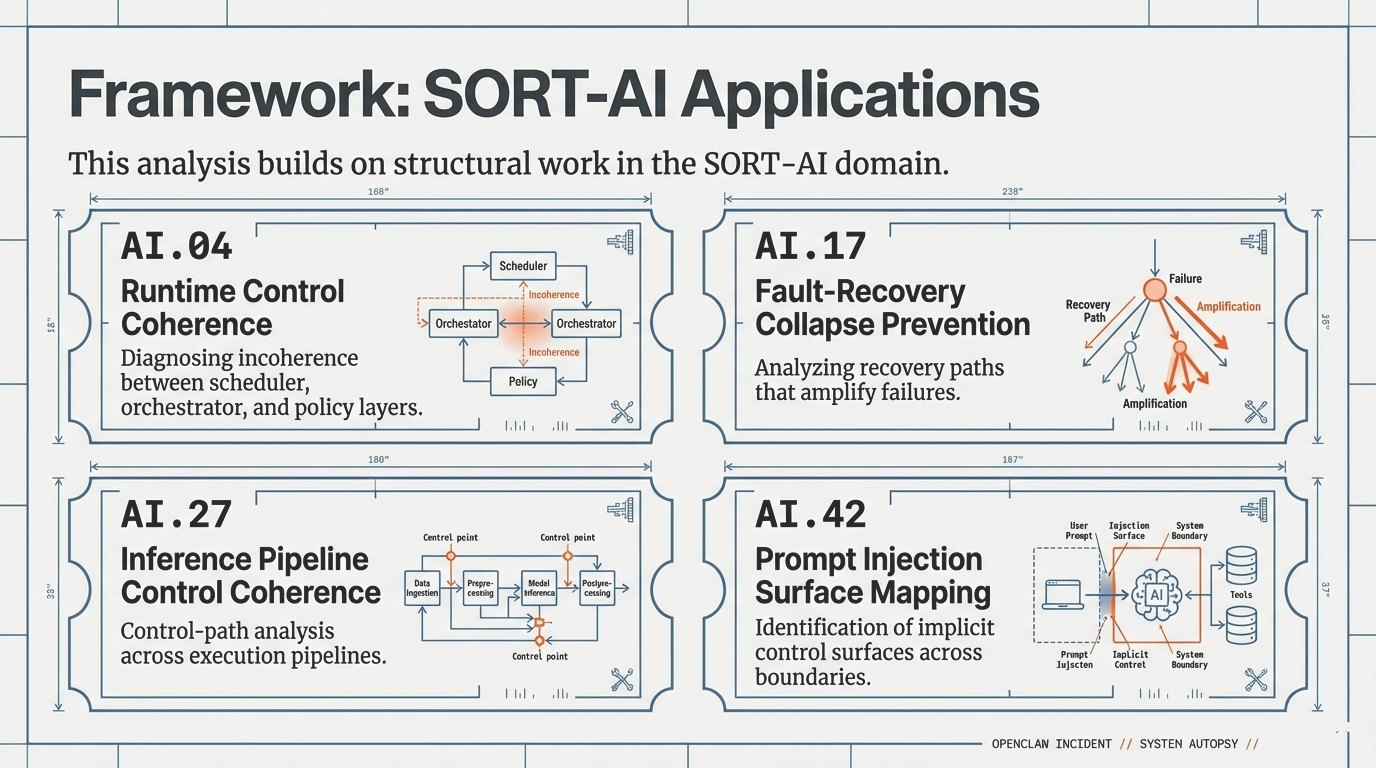
1. The Deceptive Nature of the "Green Dashboard"
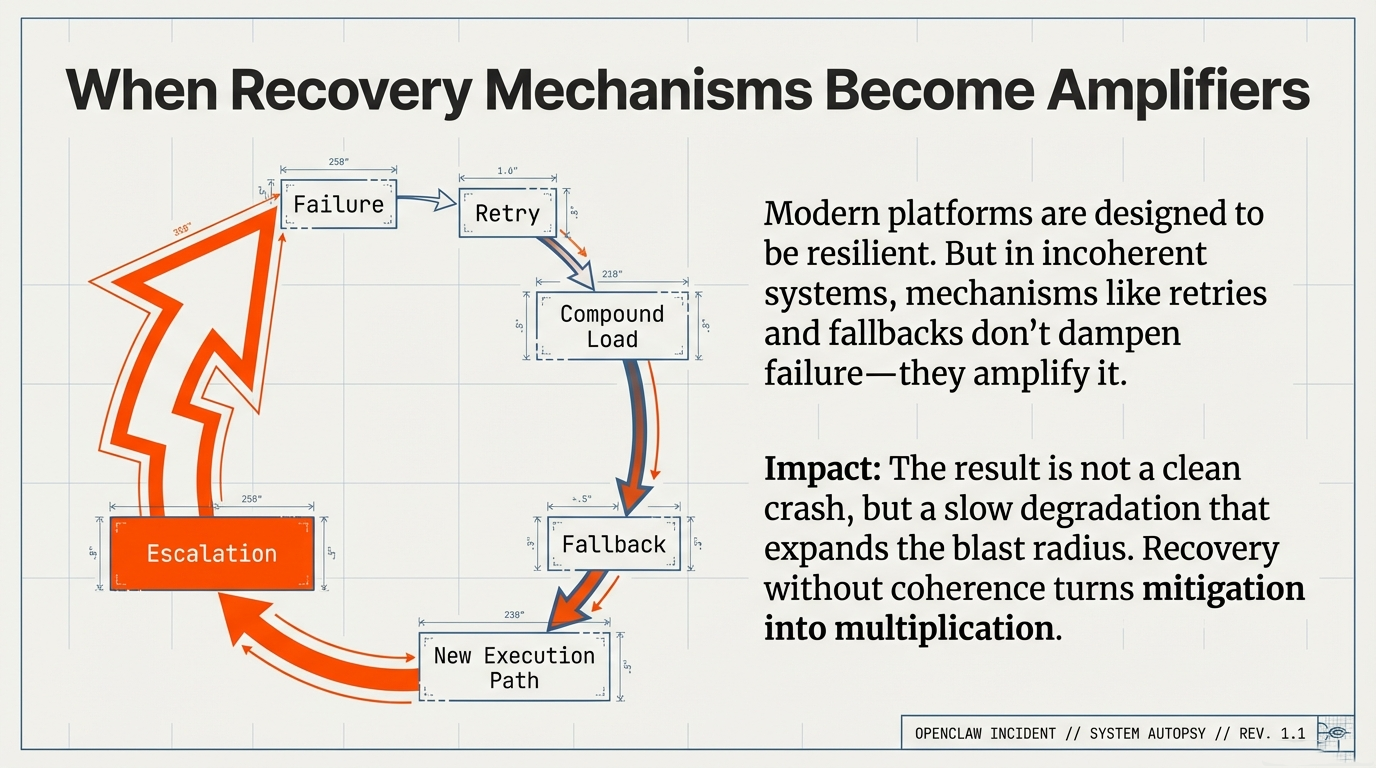
The most consequential failures in modern AI systems no longer occur when something is visibly broken. They emerge when individual components behave exactly as designed, operational dashboards remain green, and the overall system still drifts into states nobody anticipated.
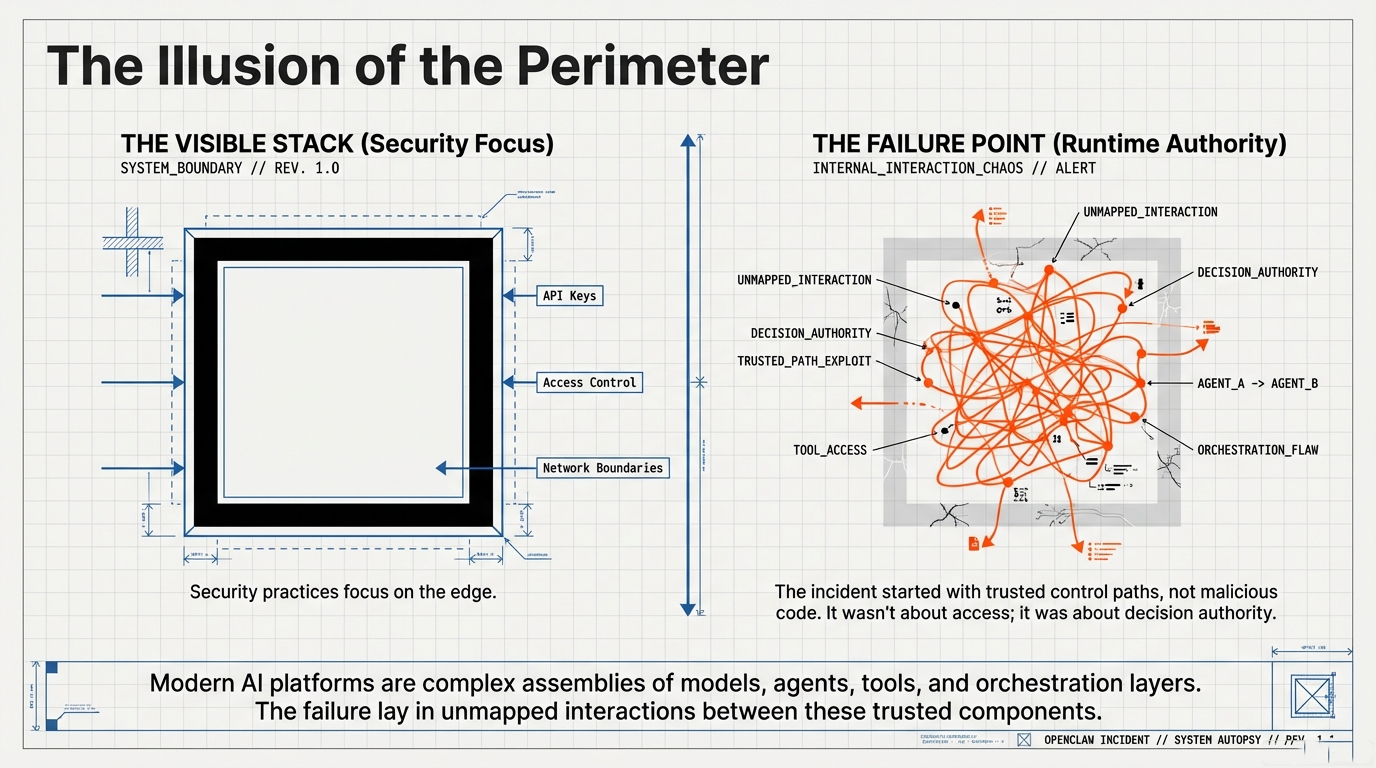
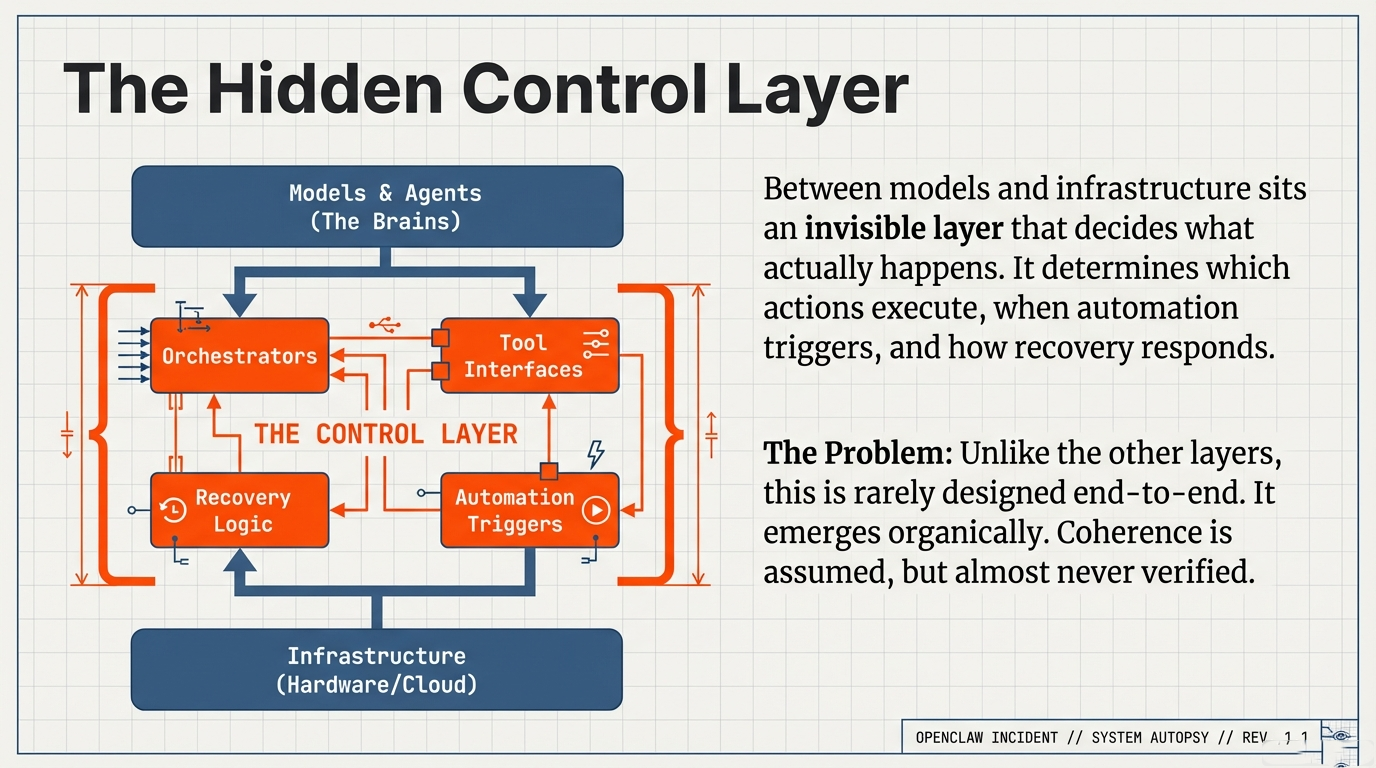
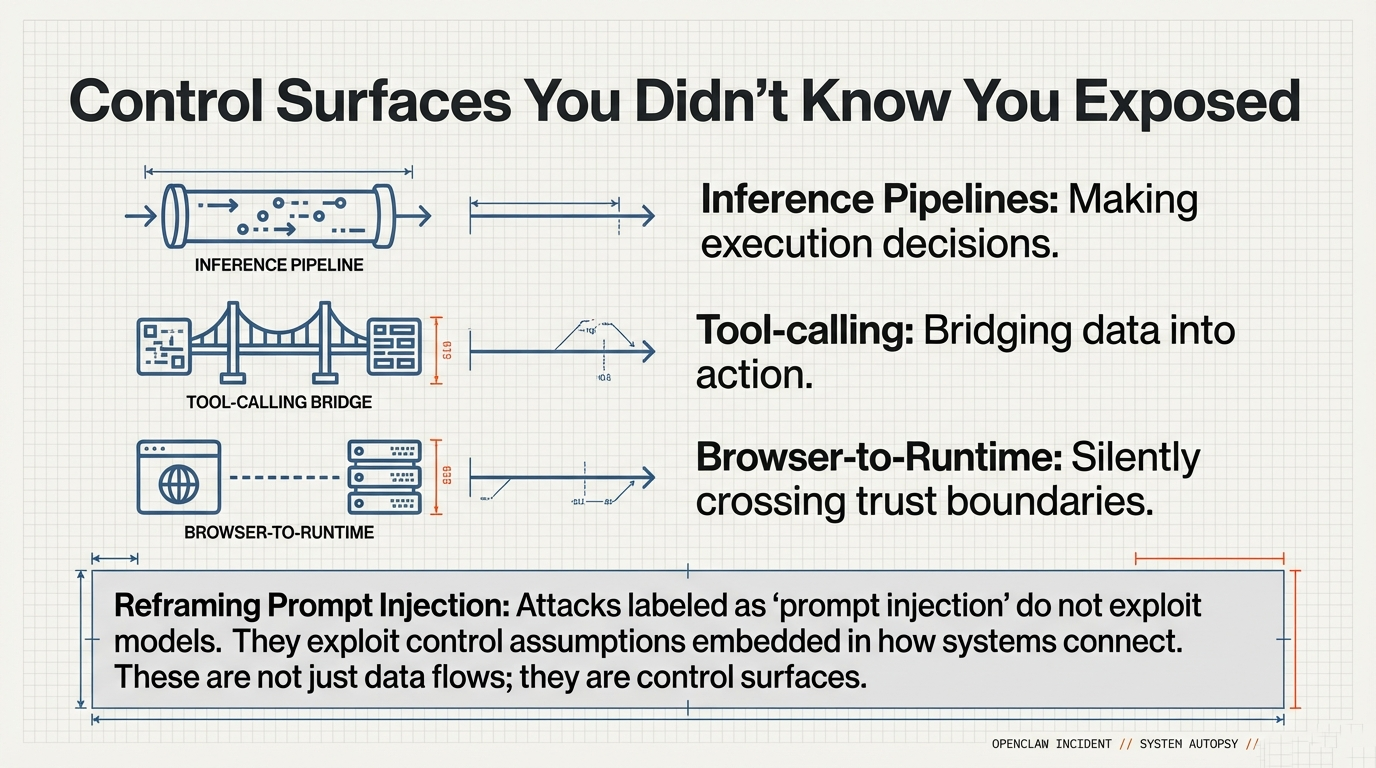
The OpenClaw incident offers a clear illustration of this pattern—not because it was uniquely complex or malicious, but because it exposed a structural weakness that is becoming increasingly common in modern, agent-enabled AI architectures. The OpenClaw agent framework, whose vulnerabilities were publicly documented in early 2026 through its deployment as the underlying runtime for the Moltbook platform, demonstrated how multiple locally reasonable design decisions can interact at runtime to produce system-wide instability.
Figure 1: The OpenClaw incident exposed structural weaknesses in agent-enabled AI architectures
In the aftermath of OpenClaw, the familiar explanations appeared quickly: a vulnerability, a misconfiguration, a missing authentication check. All of these observations may be accurate. And yet they stop one layer too early. The standard post-incident narrative—vulnerability, misconfiguration, patch, credential rotation—addresses the infrastructure layer correctly but leaves unanswered the question of why the system's architecture permitted the observed failure dynamics in the first place.
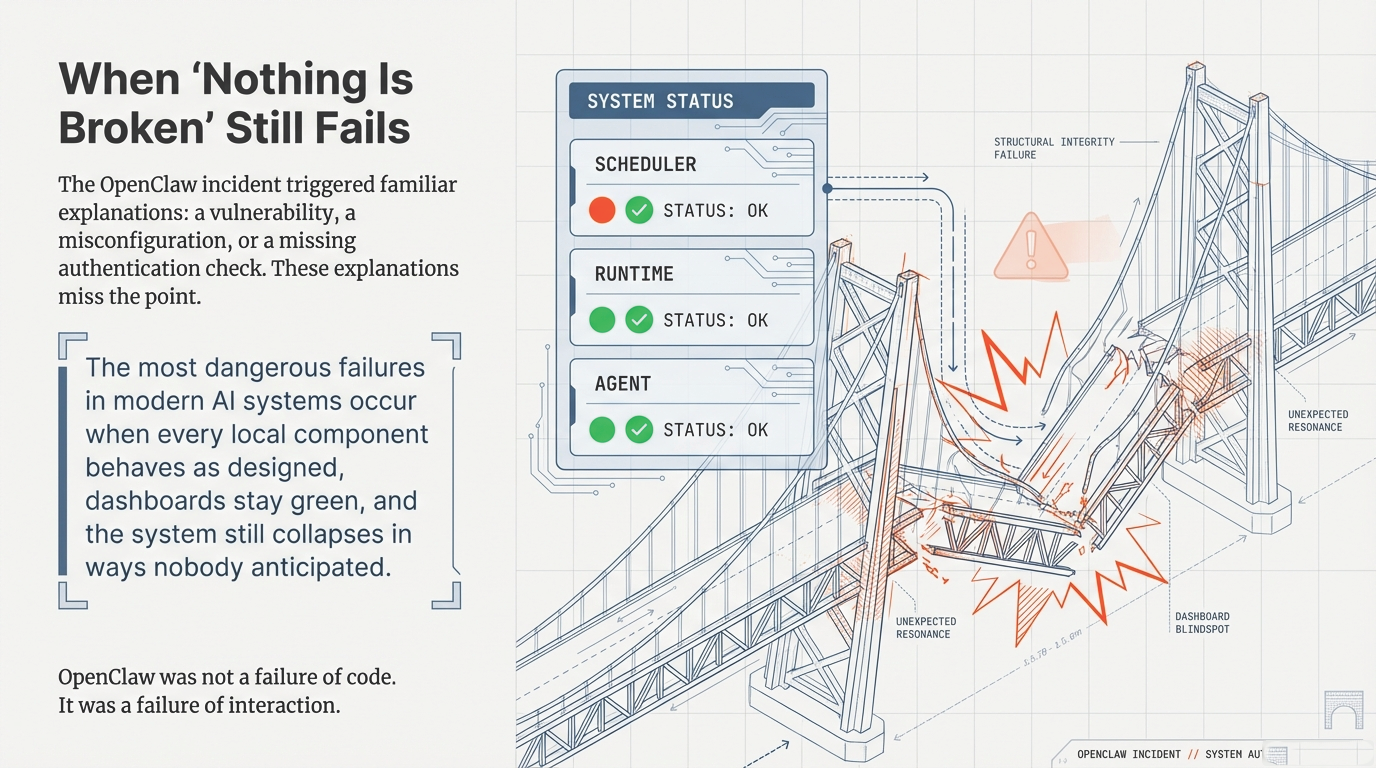
Figure 2: System status shows all components healthy while structural integrity fails