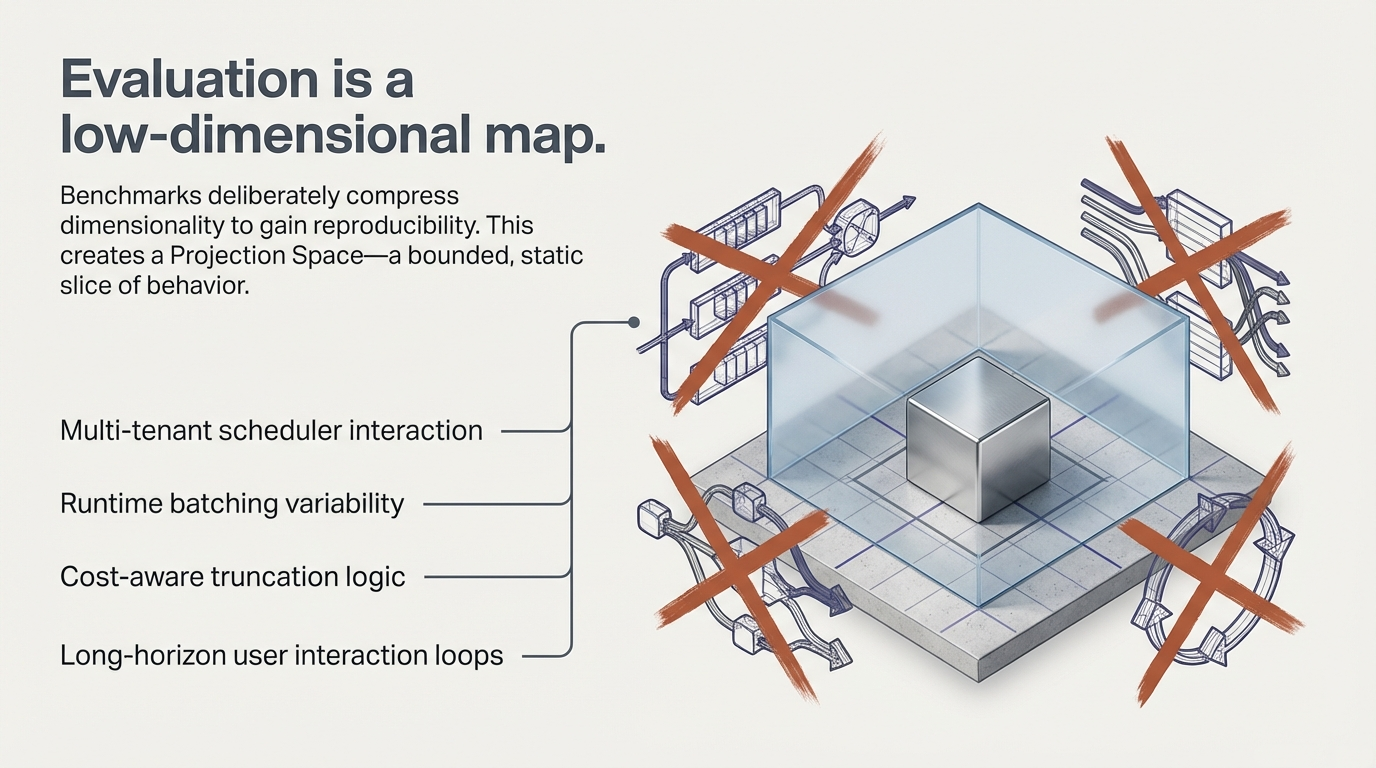
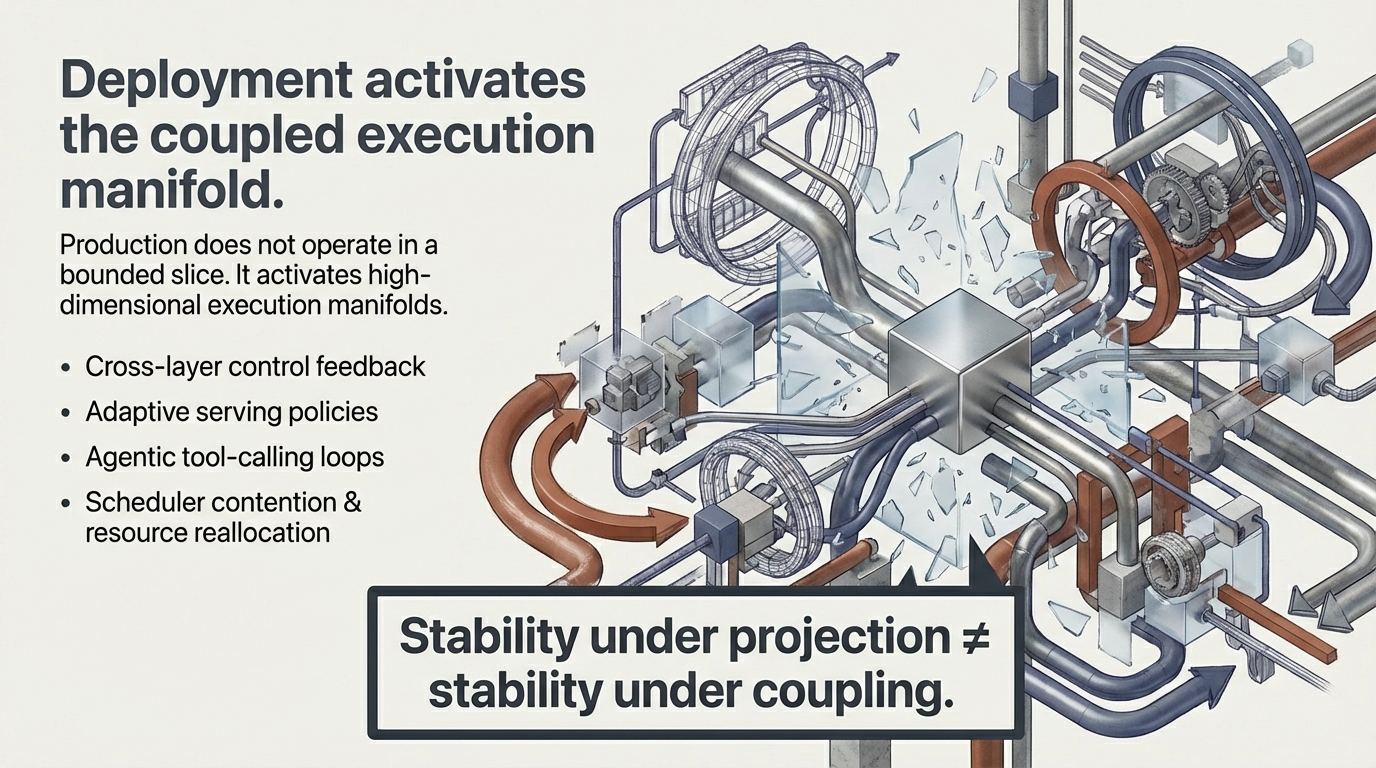
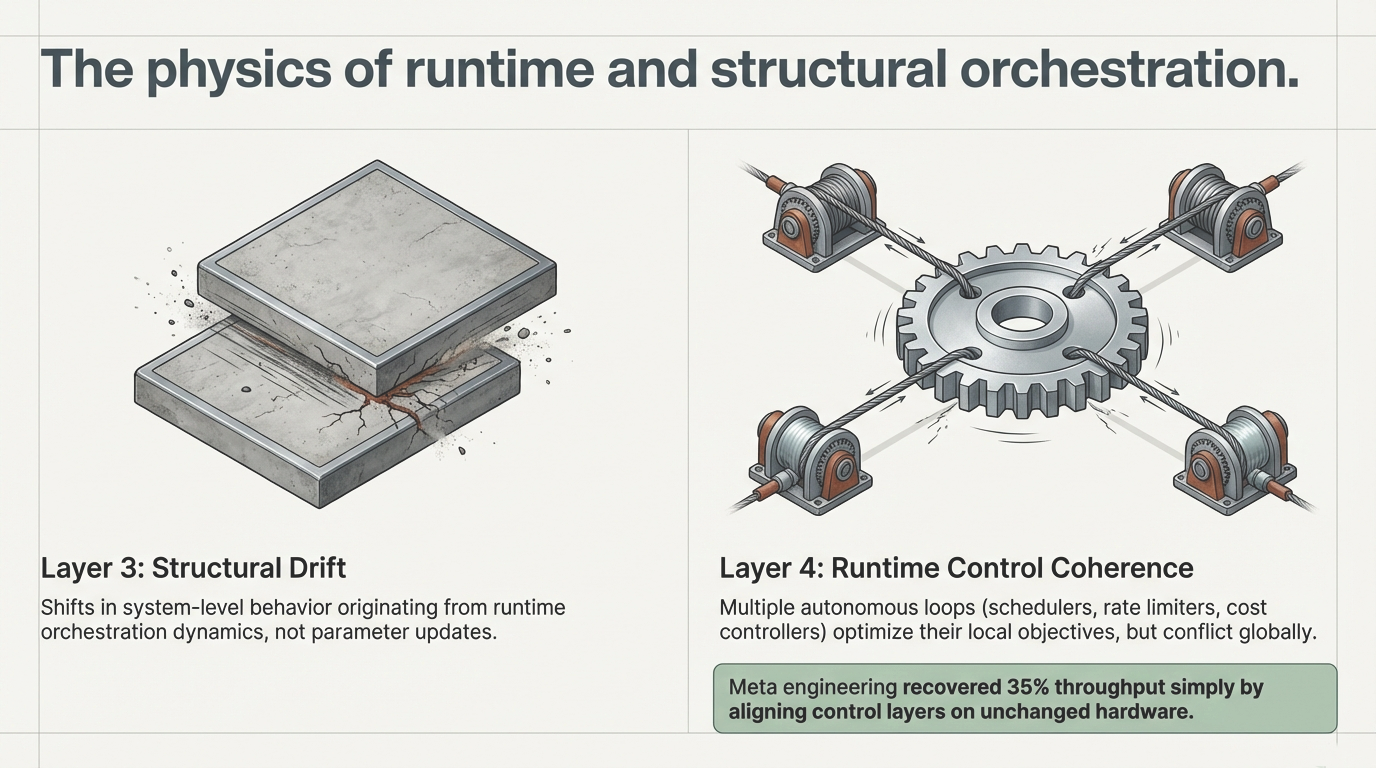
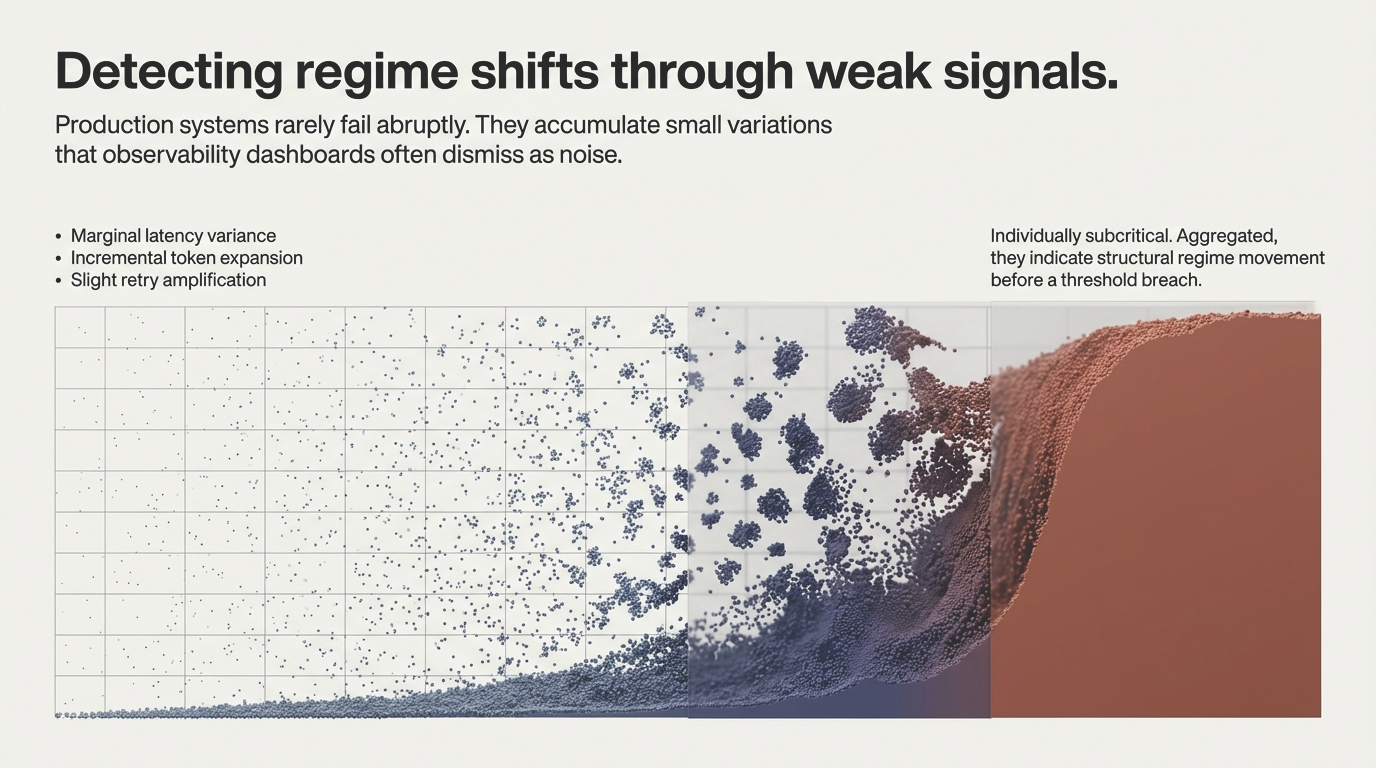
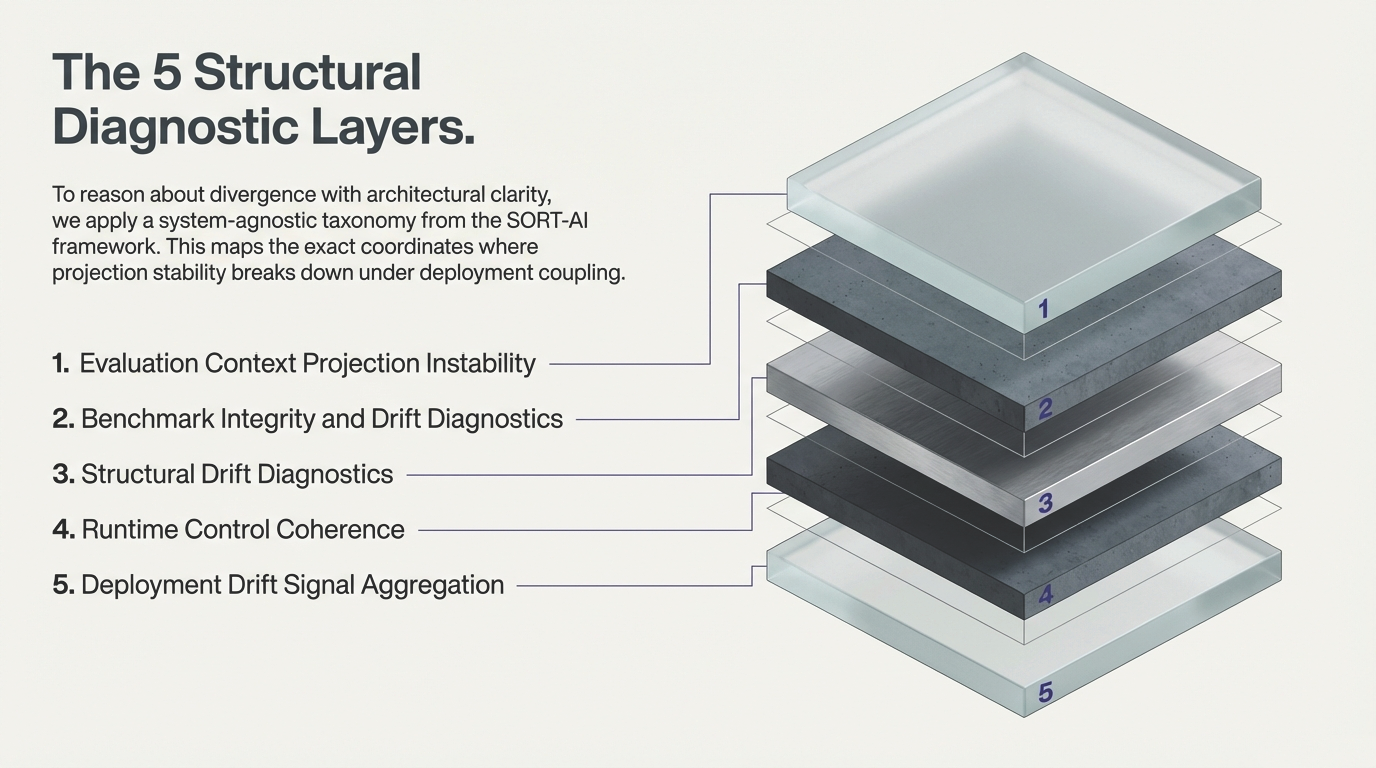
1. The Illusion of Stability
Your model passed MMLU. It cleared HumanEval. It survived red-team prompts. Your safety dashboard is green. Then week three in production arrives.
Latency variance increases. Retry patterns amplify. Behavior becomes subtly different under sustained interaction. Nothing changed in the weights.

Figure 1: Strong evaluation results. Different behavior under deployment coupling. No changes to model weights.
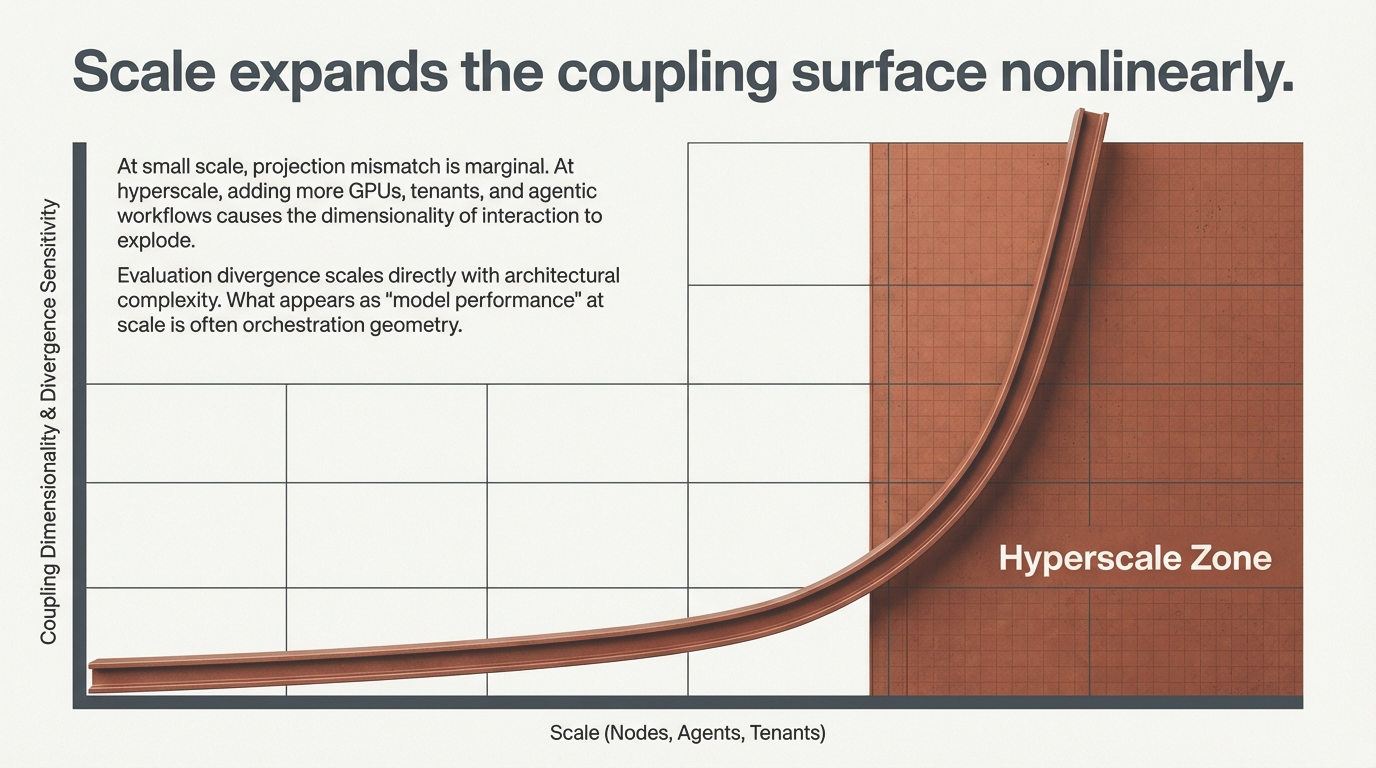
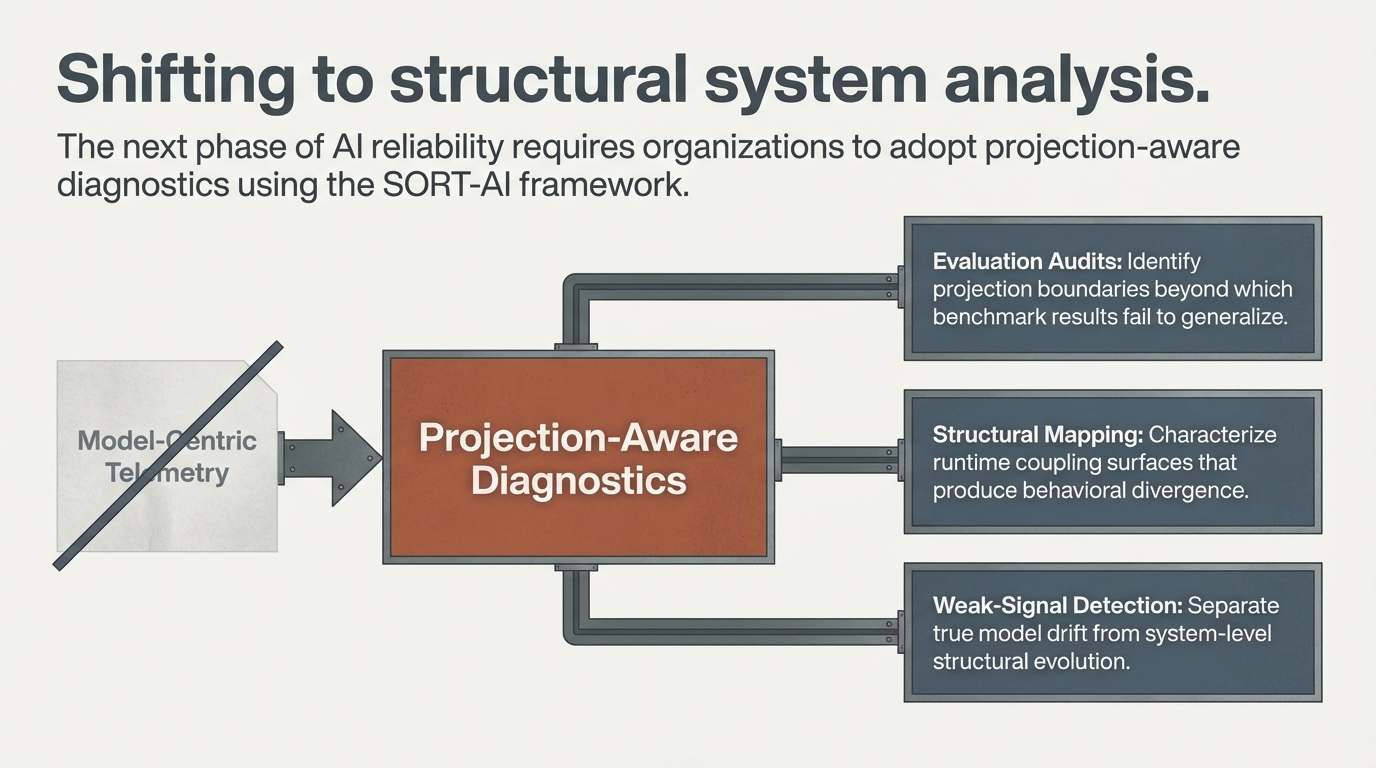
The postmortem usually asks: Was it alignment fragility? Benchmark gaming? Model drift? In many cases, the underlying pattern is simpler—and more structural. The system that was tested is not the system that was deployed. What was tested is a projection of it.

Figure 2: Evaluation–deployment divergence is not a model property. It is a structural non-equivalence between two distinct system spaces.