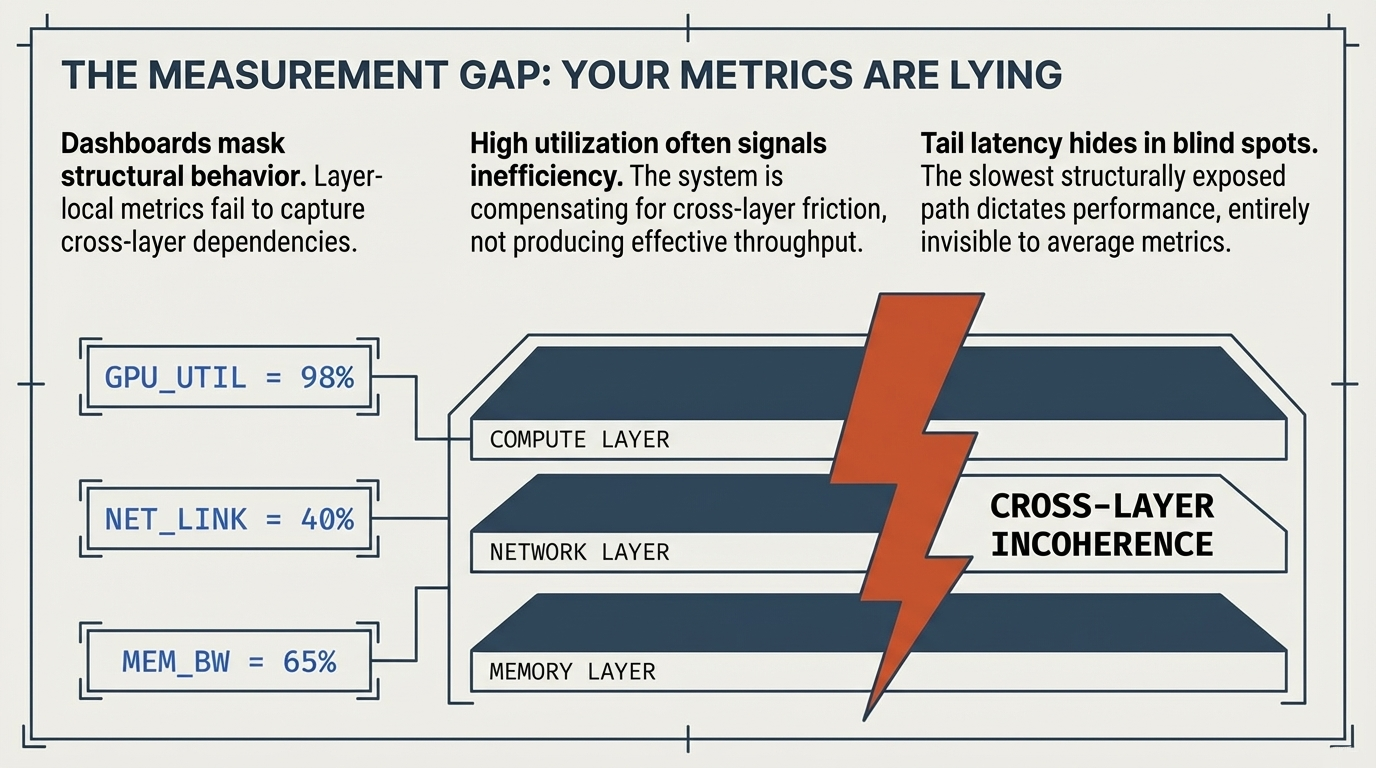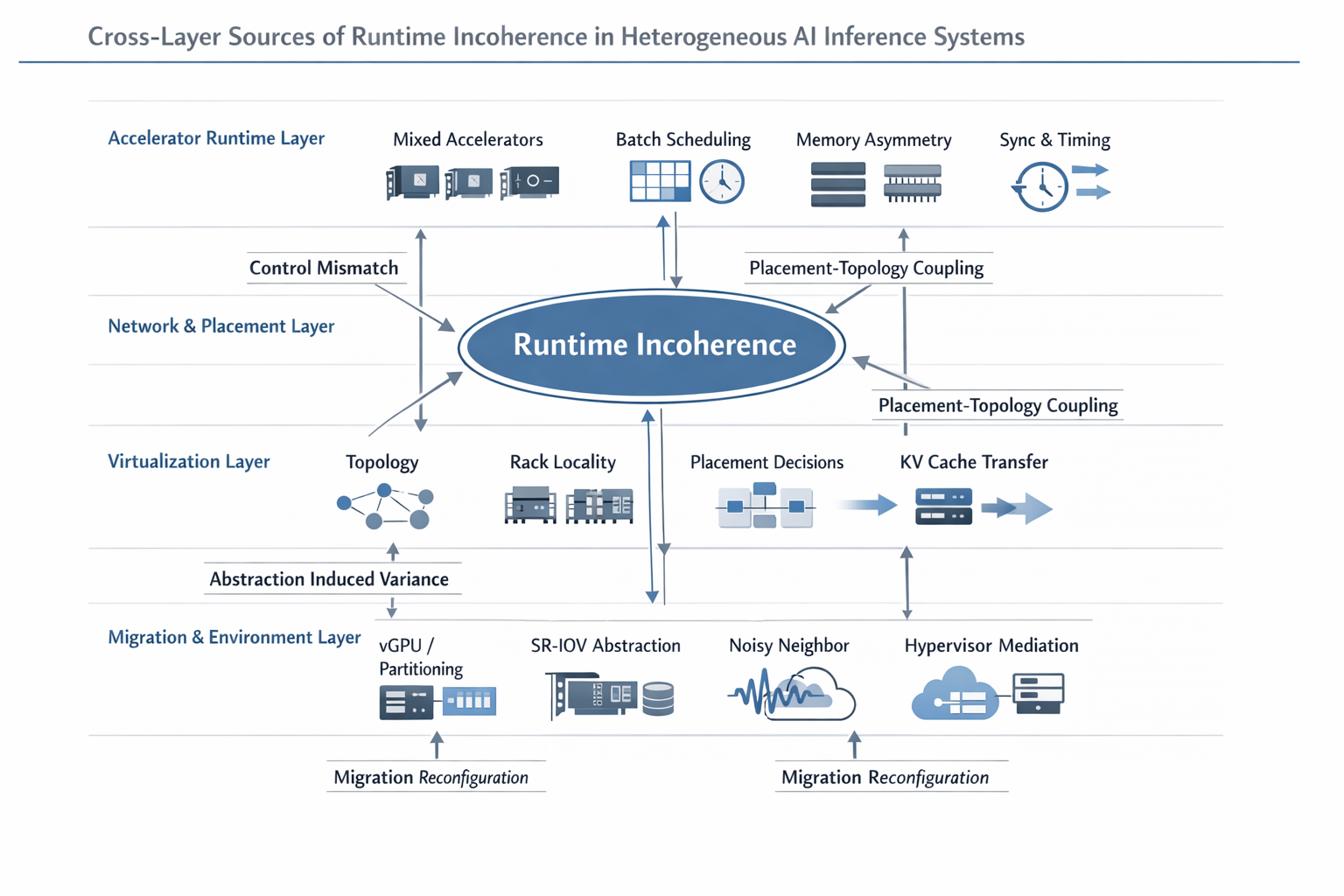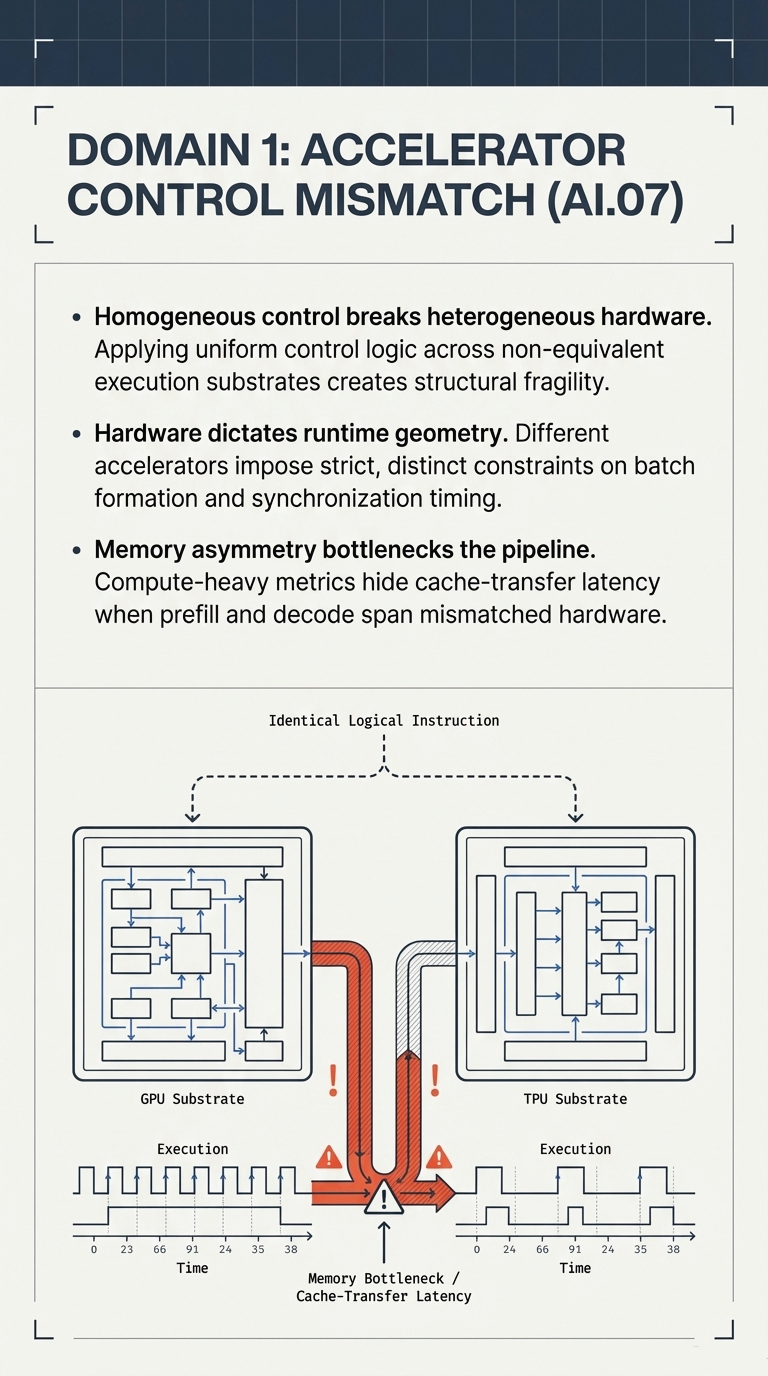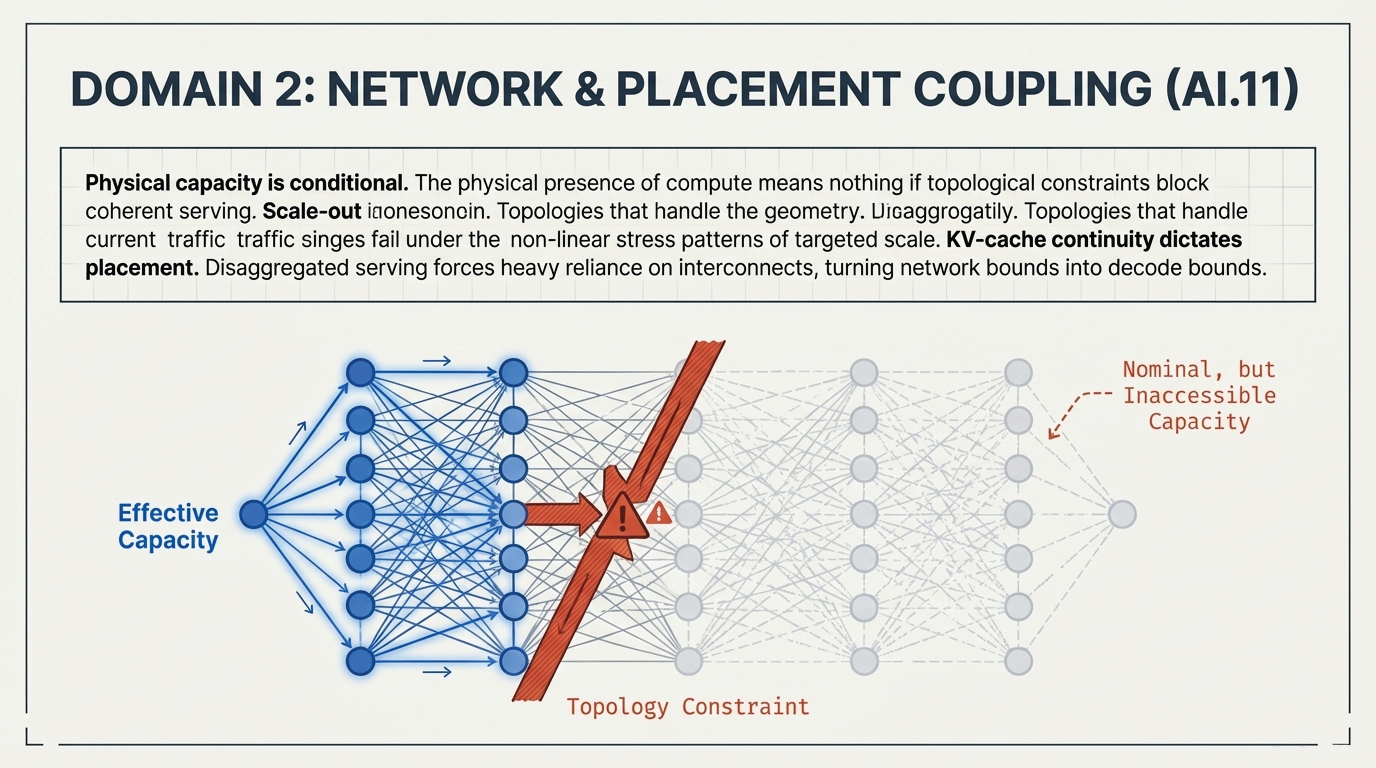
1. From Homogeneous Fleets to Heterogeneous Inference Fabrics
Earlier AI infrastructure regimes were frequently organized around relatively homogeneous accelerator fleets, bounded network assumptions, and comparatively stable runtime conditions. Under those conditions, performance reasoning could often proceed through localized constraints: device saturation, memory pressure, or interconnect bottlenecks within a mostly uniform execution fabric.
That assumption is becoming progressively less adequate. Contemporary inference systems are increasingly assembled from mixed accelerator classes, heterogeneous memory paths, disaggregated serving stages, virtualized execution layers, and placement patterns that extend across cloud, region, and provider boundaries.
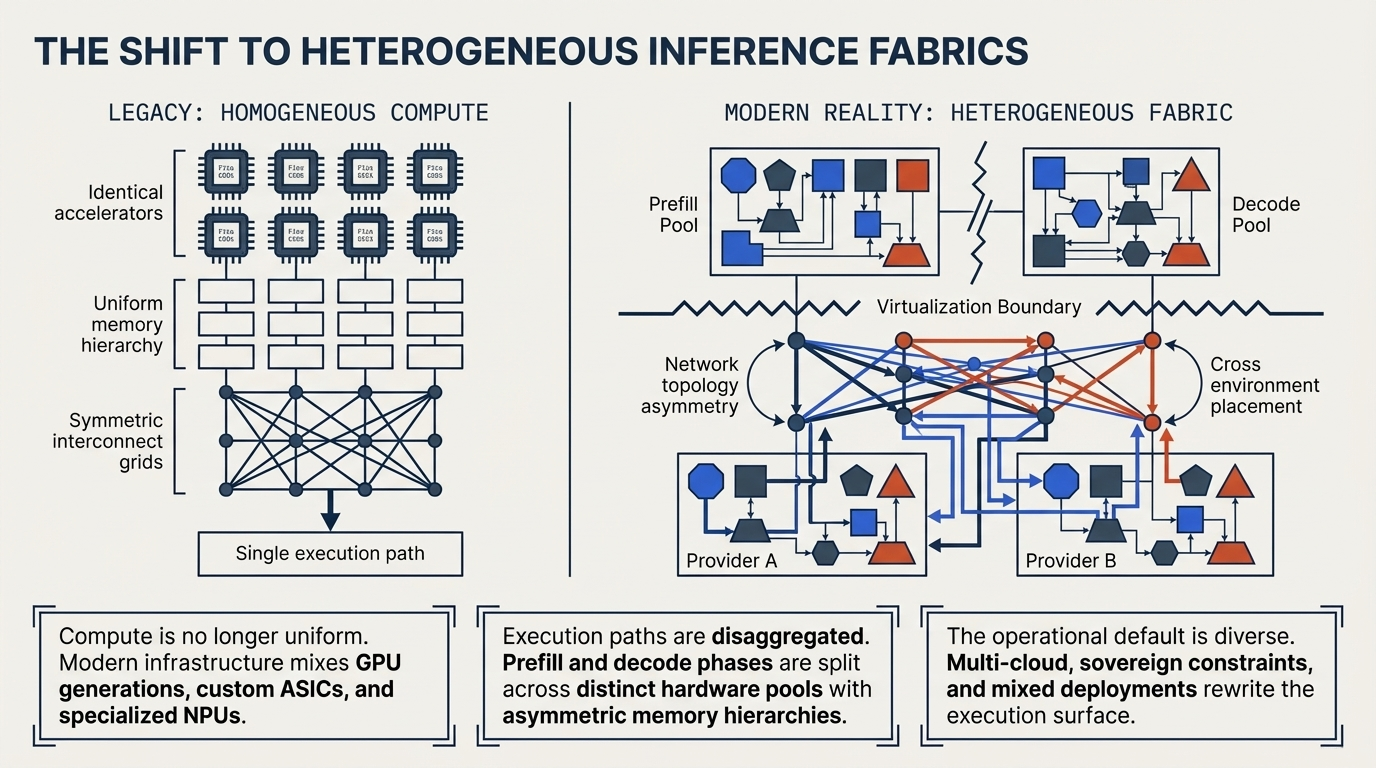
Figure 1: From legacy homogeneous compute to modern heterogeneous inference fabrics. Compute is no longer uniform. Execution paths are disaggregated. Multi-cloud and sovereign constraints rewrite the execution surface.
The drivers are structural rather than incidental. Economic pressure encourages workload placement across different accelerator tiers. Supply constraints make mixed-generation procurement increasingly common. Prefill and decode phases may be separated across distinct resources. Hybrid deployment patterns distribute workloads across edge, regional, and centralized cloud environments.