AI Systems Do Not Lack Signals
Modern AI infrastructure teams already work with a wide range of diagnostic inputs: throughput, latency, tail behavior, accelerator utilization, memory pressure, queueing effects, scheduler behavior, retry counts, failure rates, routing patterns, cost per output, benchmark results, safety evaluations, audit traces, and deployment records. These signals are necessary. Without them, no serious operational or scientific assessment of an AI system is possible. But they are not sufficient by themselves.

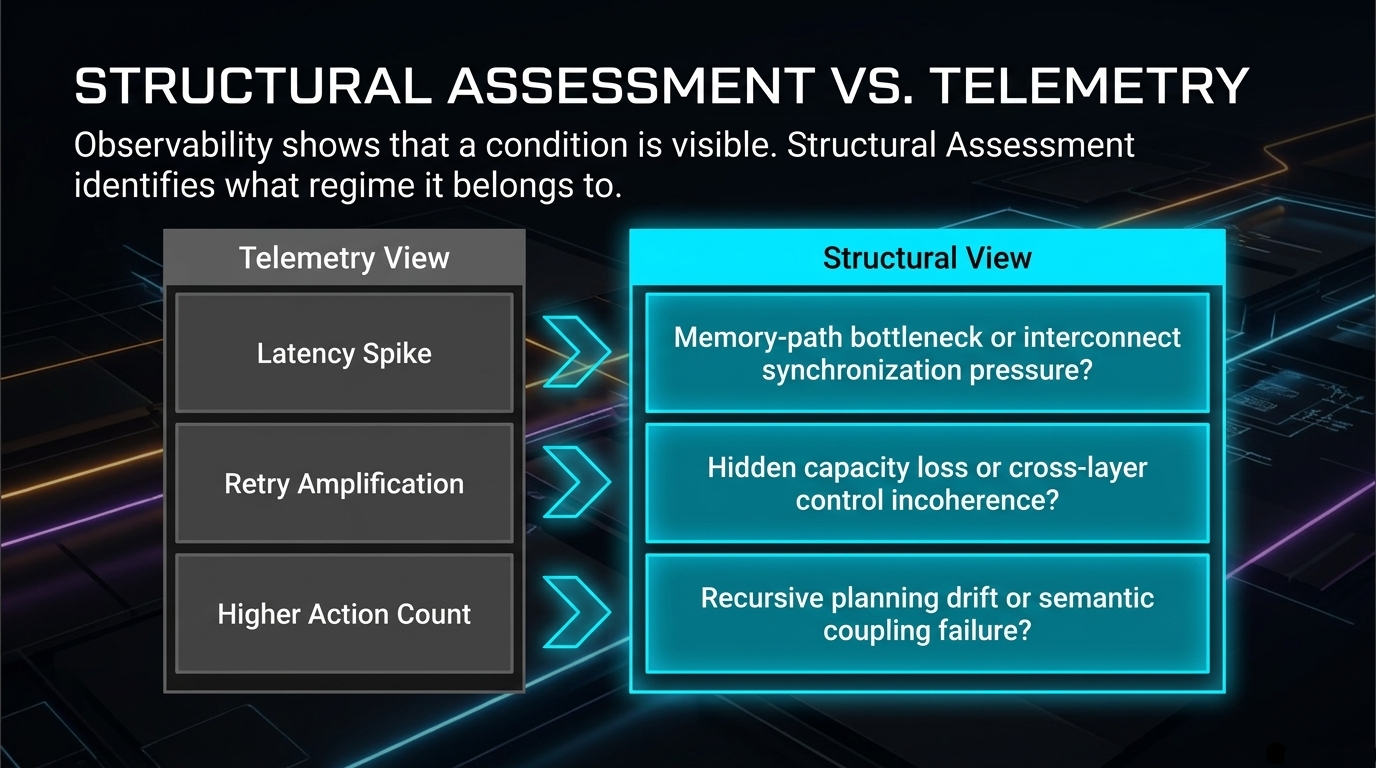
The observability trap: AI fabrics are densely instrumented, yet dense instrumentation does not automatically produce structural classification.
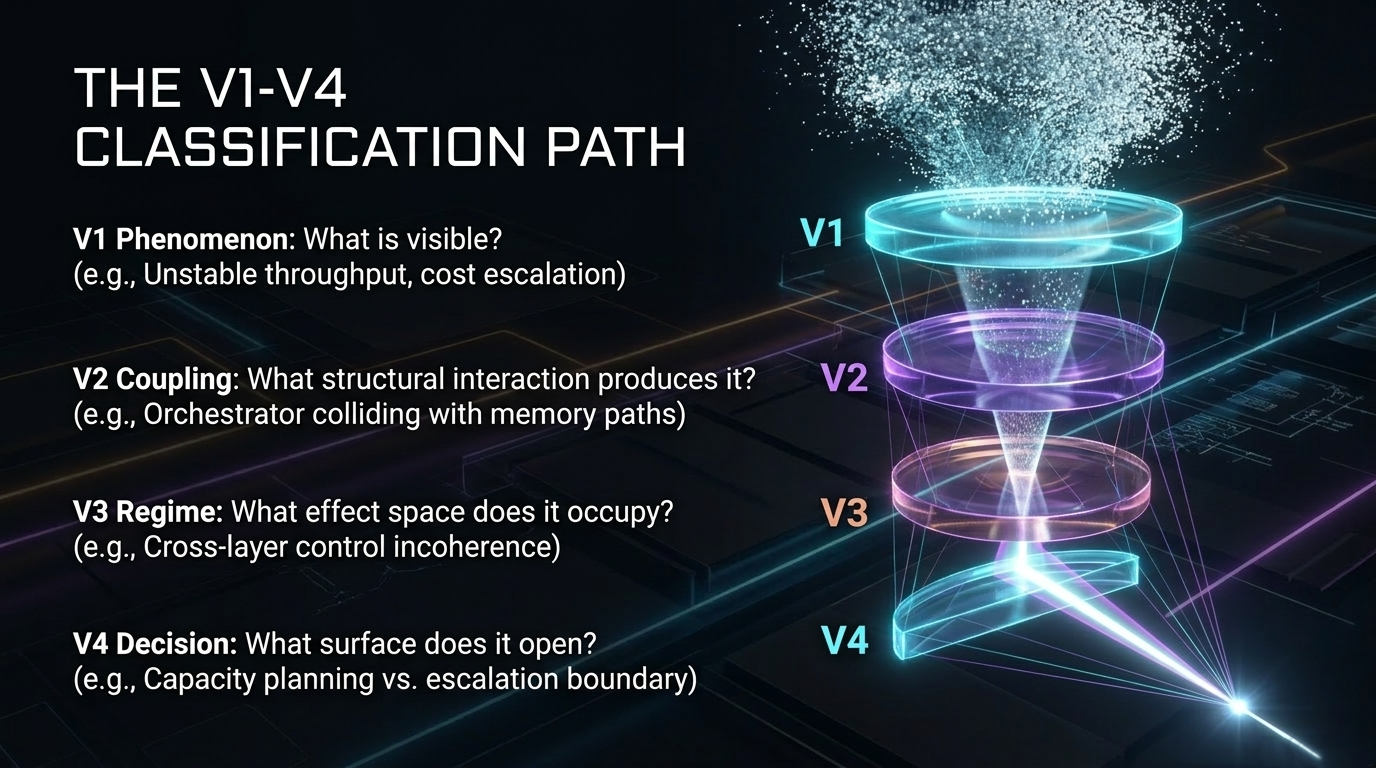
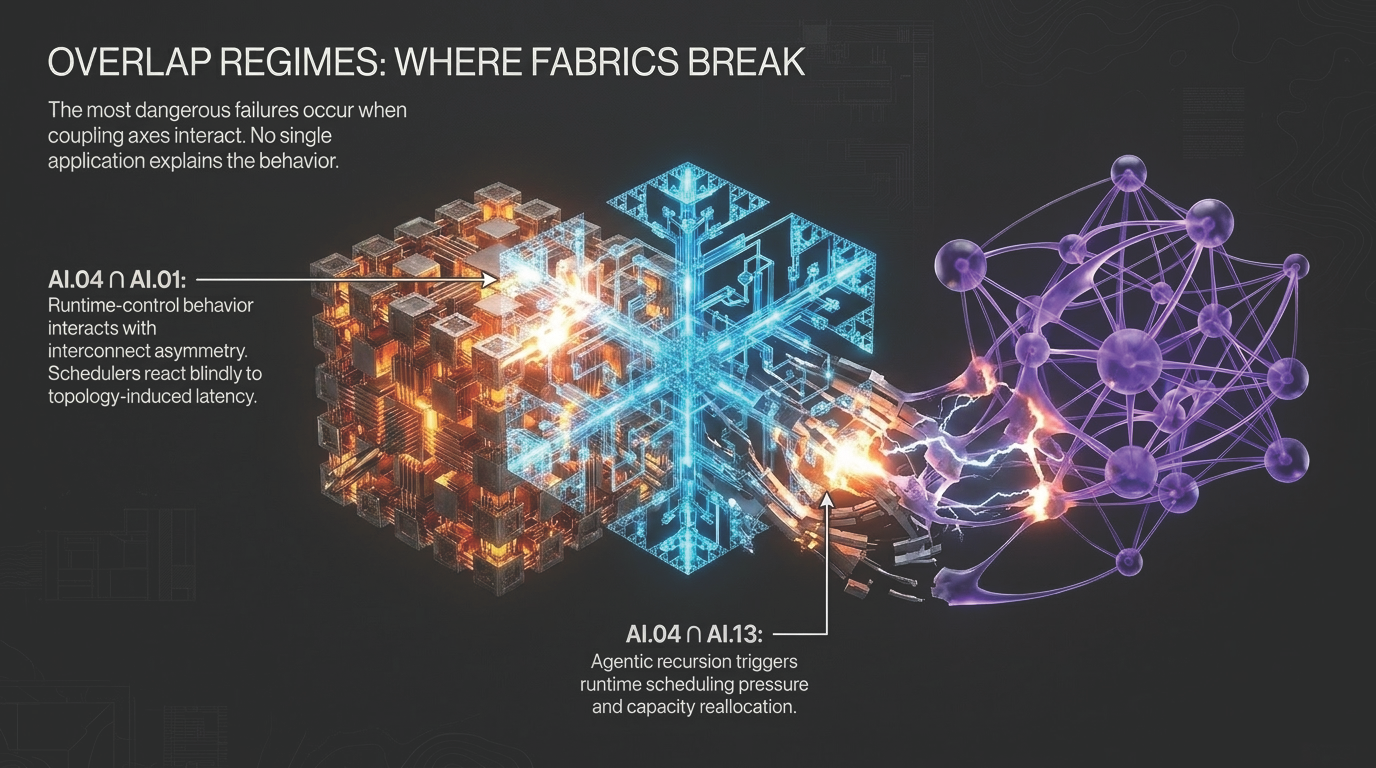
The reason is structural. Advanced AI systems are no longer isolated model instances. They are composed execution fabrics. Model execution, serving layers, schedulers, orchestrators, memory paths, runtime engines, policy mechanisms, tool chains, agentic workflows, and evidence surfaces interact across multiple layers. Each layer can remain locally functional while the composed system develops behavior that is difficult to explain from any one signal alone.

Local correctness does not guarantee global coherence. A component can behave as designed while the composed system becomes less predictable.
None of the following patterns necessarily means a component is broken — they indicate that the relevant object of analysis is no longer only the component, but the composed system condition:
Stable utilization, declining effective capacity
A system may show stable average utilization while effective capacity becomes inaccessible. The utilization curve is valid; what it instantiates structurally is not yet classified.
Successful retries, growing effective load
A runtime may complete more requests while consuming a disproportionate retry budget. The retry counter indicates resilience, but it may also conceal cost amplification.
Valid agentic outputs, expanding tool calls
An agentic workflow may produce valid outputs while expanding the number of intermediate tool calls or verification loops. Task completion remains acceptable; the structural class is ambiguous.
Strong benchmark, deployment drift
A benchmark may remain valid within its evaluation boundary while deployment behavior shifts under real runtime, orchestration, memory, policy, or tool-use pressure.
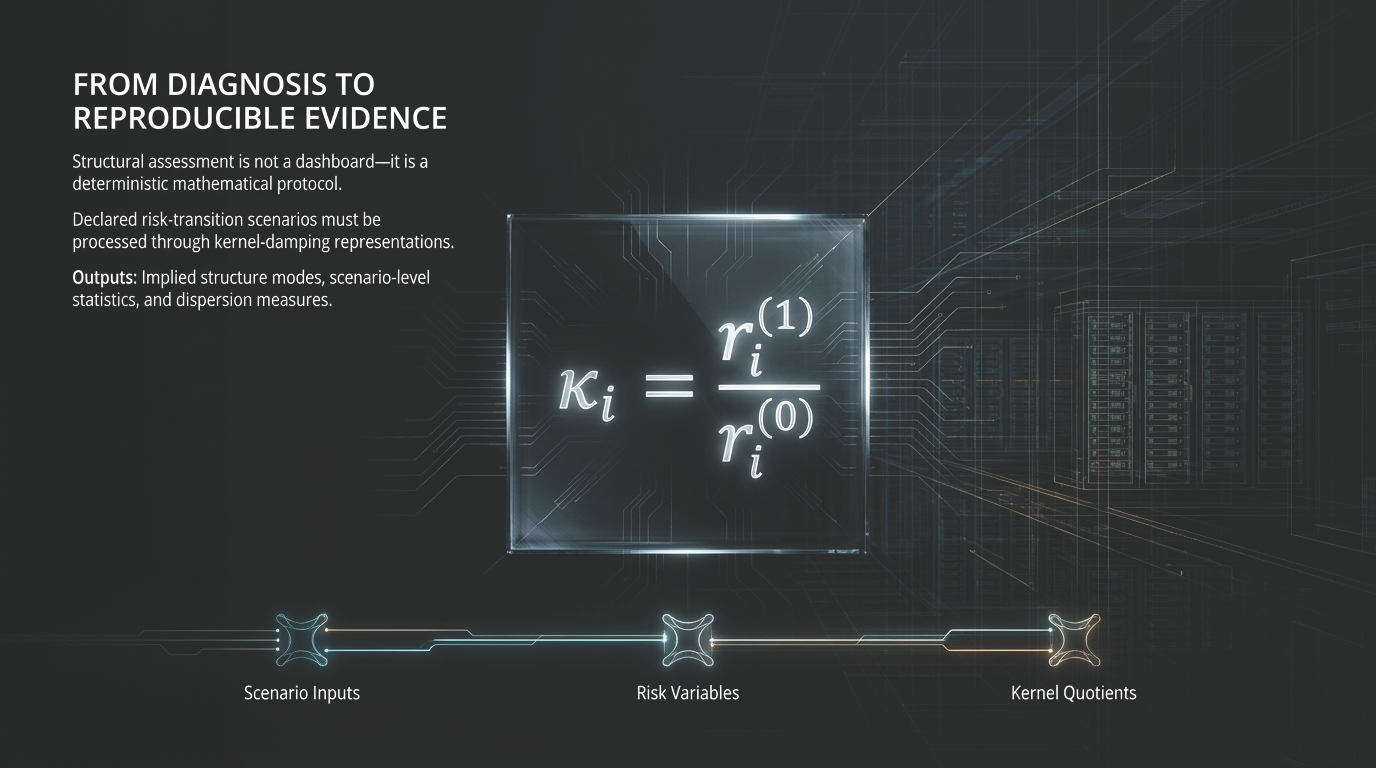
The problem is not missing data. The problem is that signals do not automatically become structural evidence.