What SORT-AI Is, and Why AI Fabrics Need It
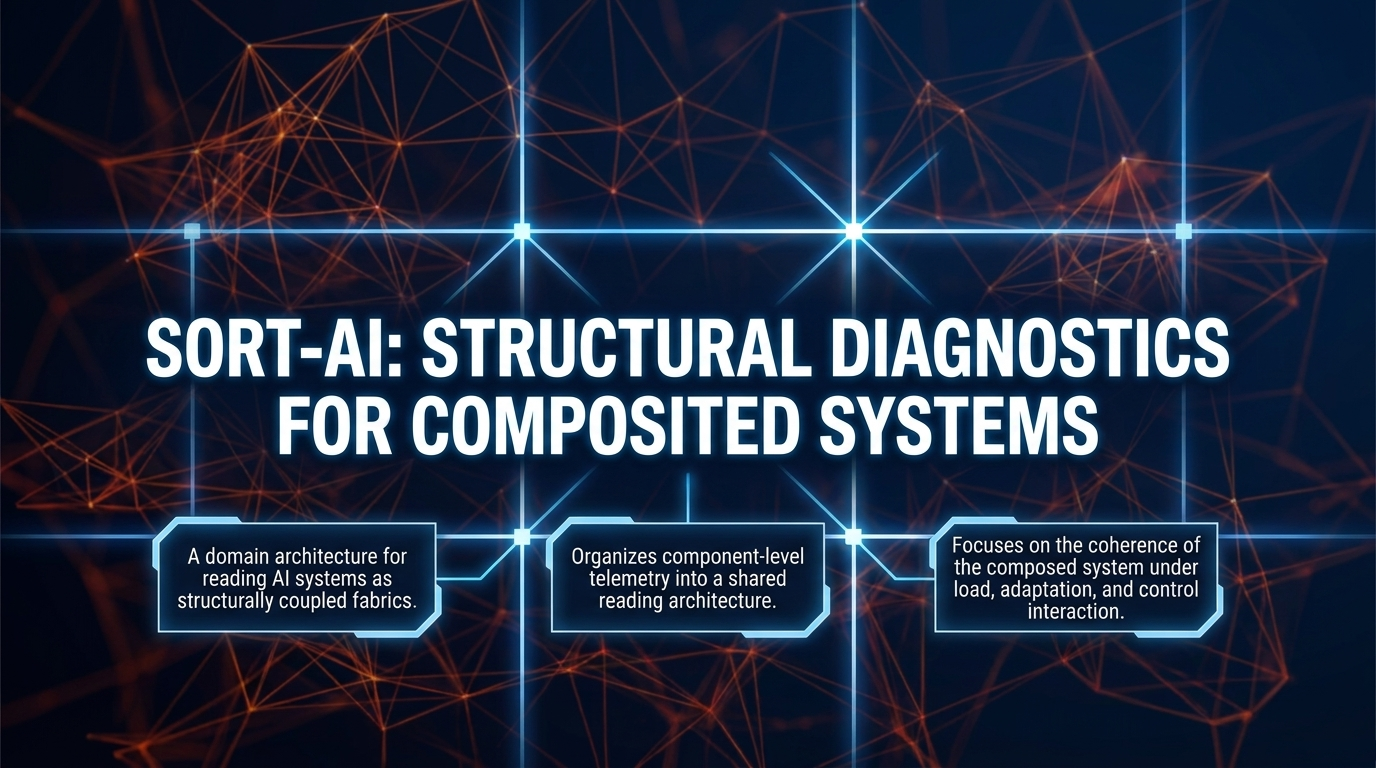
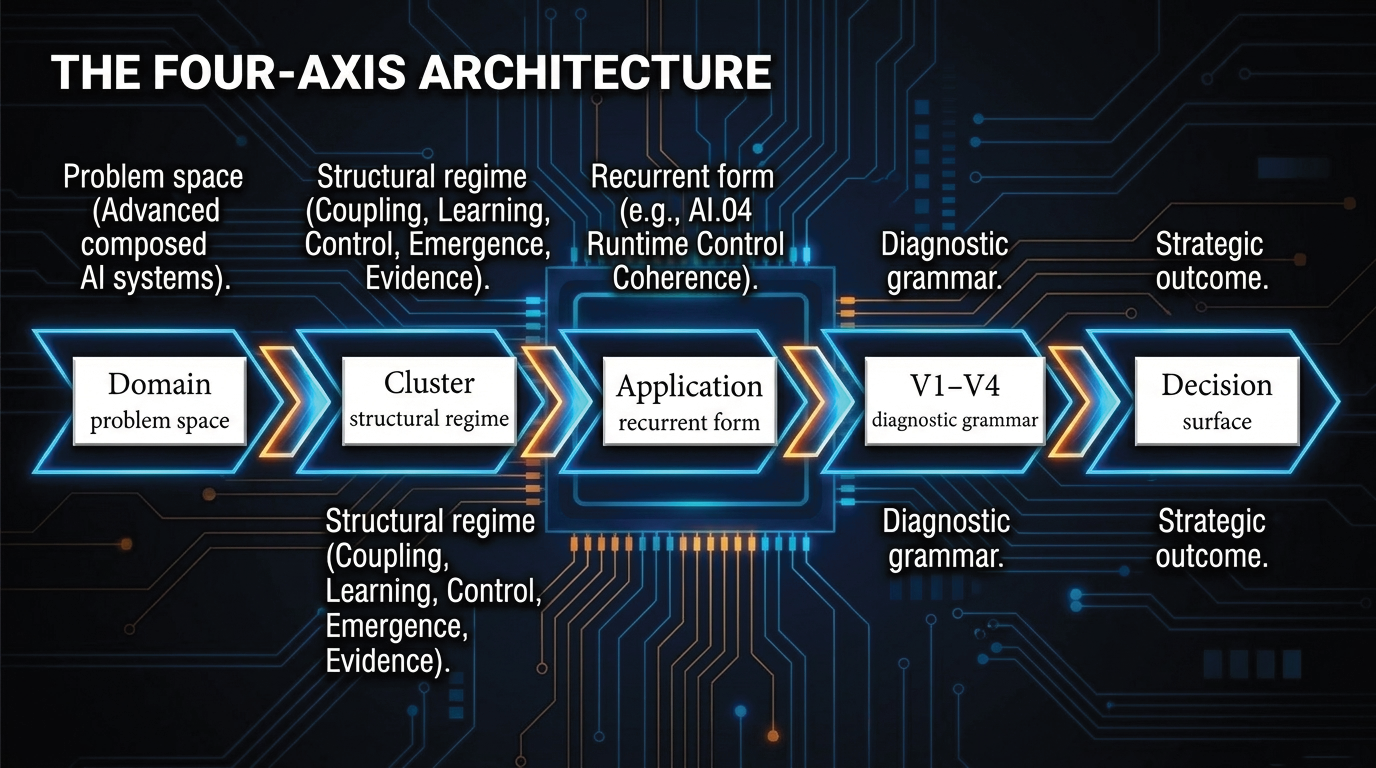
SORT-AI is a structural diagnostic framework for AI fabrics. It gives signals from benchmarks, tracing, observability, runtime monitoring, and governance one structural vocabulary.
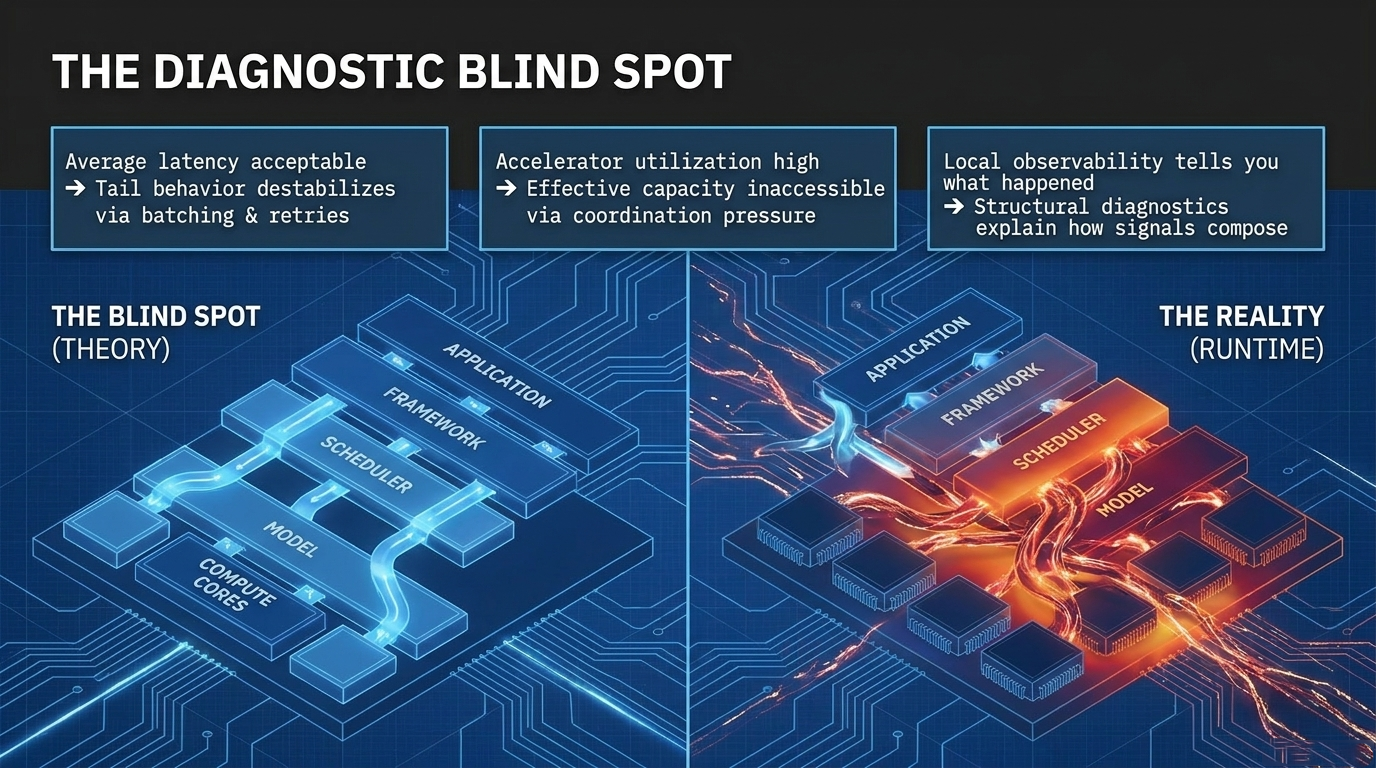
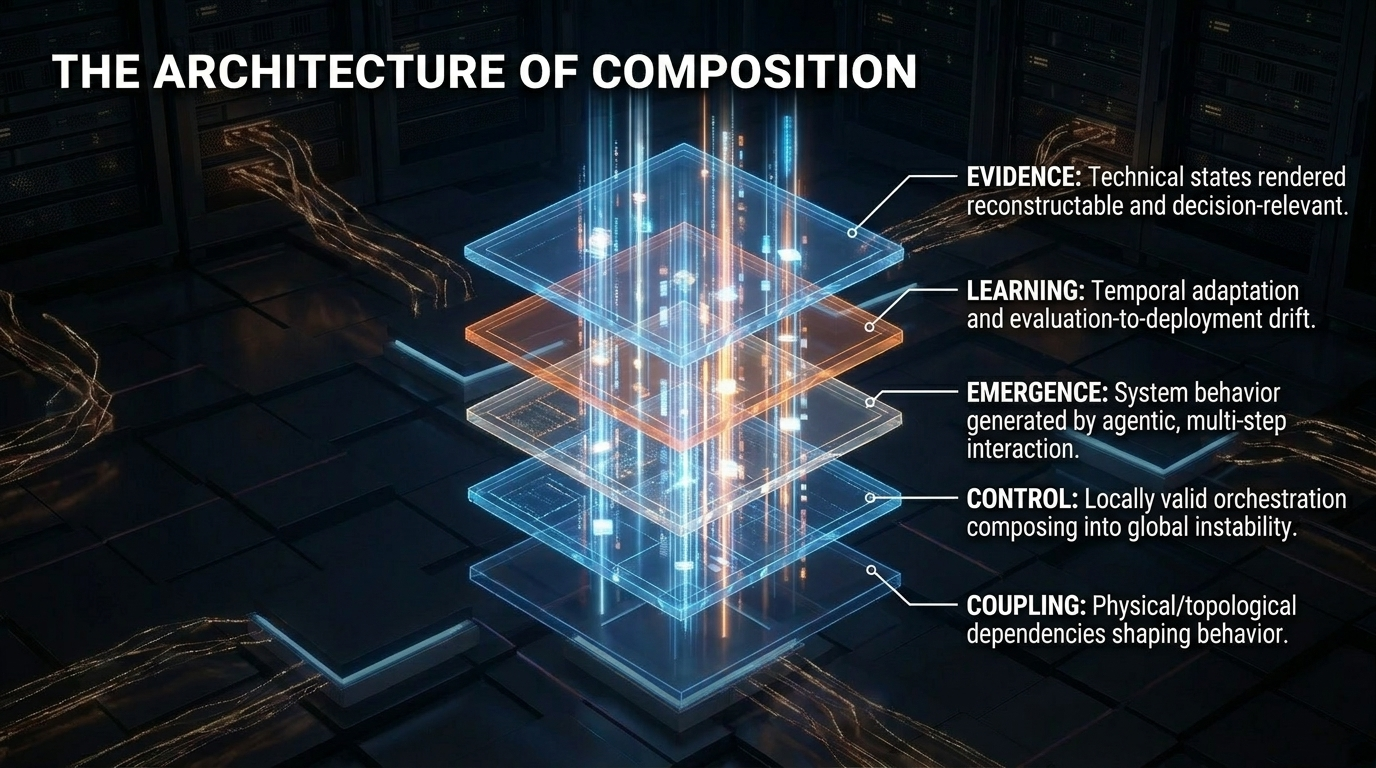
The relevant object of analysis is no longer the isolated model. A modern advanced AI system is a composed structure spanning model execution, serving layers, runtimes, schedulers, orchestrators, control planes, policy-enforcement mechanisms, tool chains, memory paths, deployment boundaries, and evidence surfaces. Each of these layers may remain locally functional while the composed system develops behavior that is not visible in any one layer.
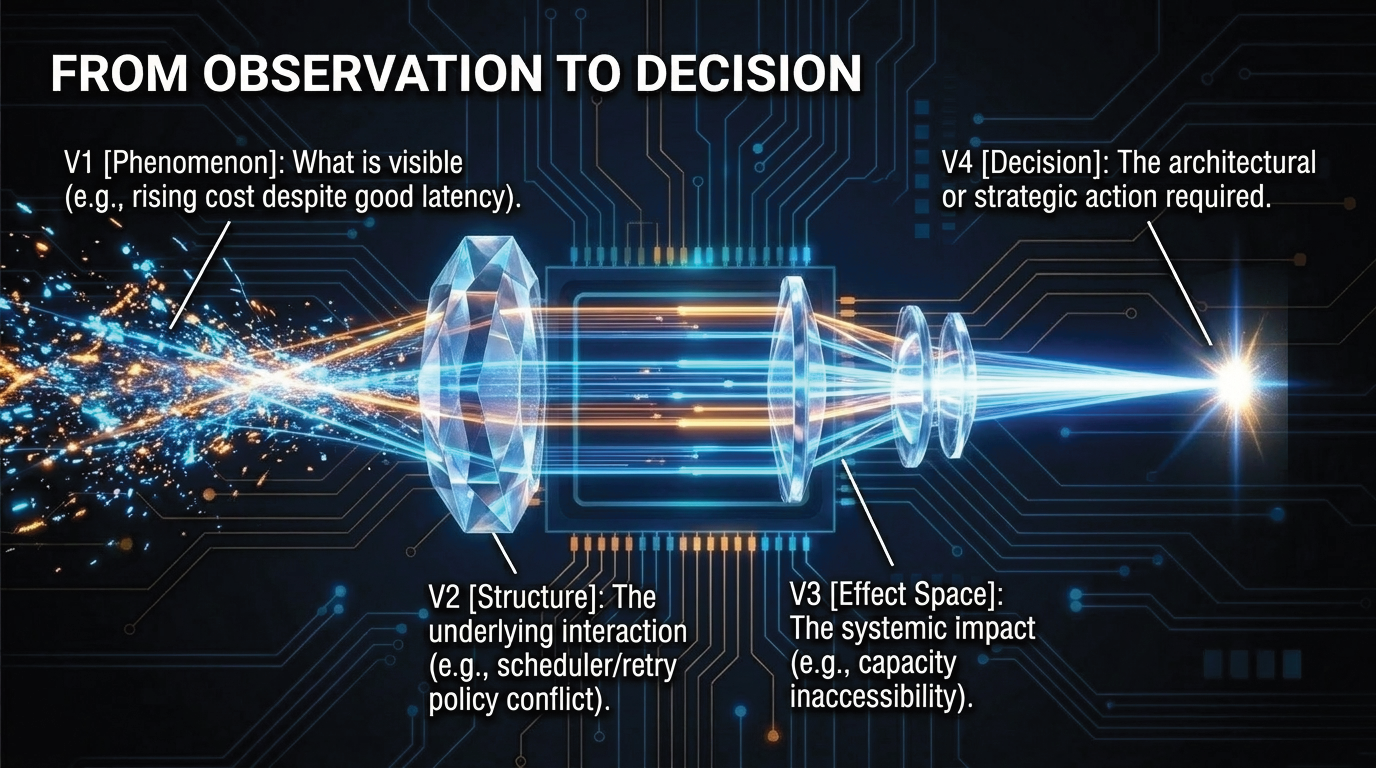
SORT-AI is not an observability platform, a scheduler, a benchmark suite, a runtime stack, a governance tool, or a replacement for existing diagnostic practice. It does not introduce new AI algorithms, runtime mechanisms, physical laws, degrees of freedom, or empirical parameters. Instead, it provides a reading architecture for composed systems whose behavior depends on coupling, control interaction, temporal adaptation, emergent coordination, and evidence requirements.
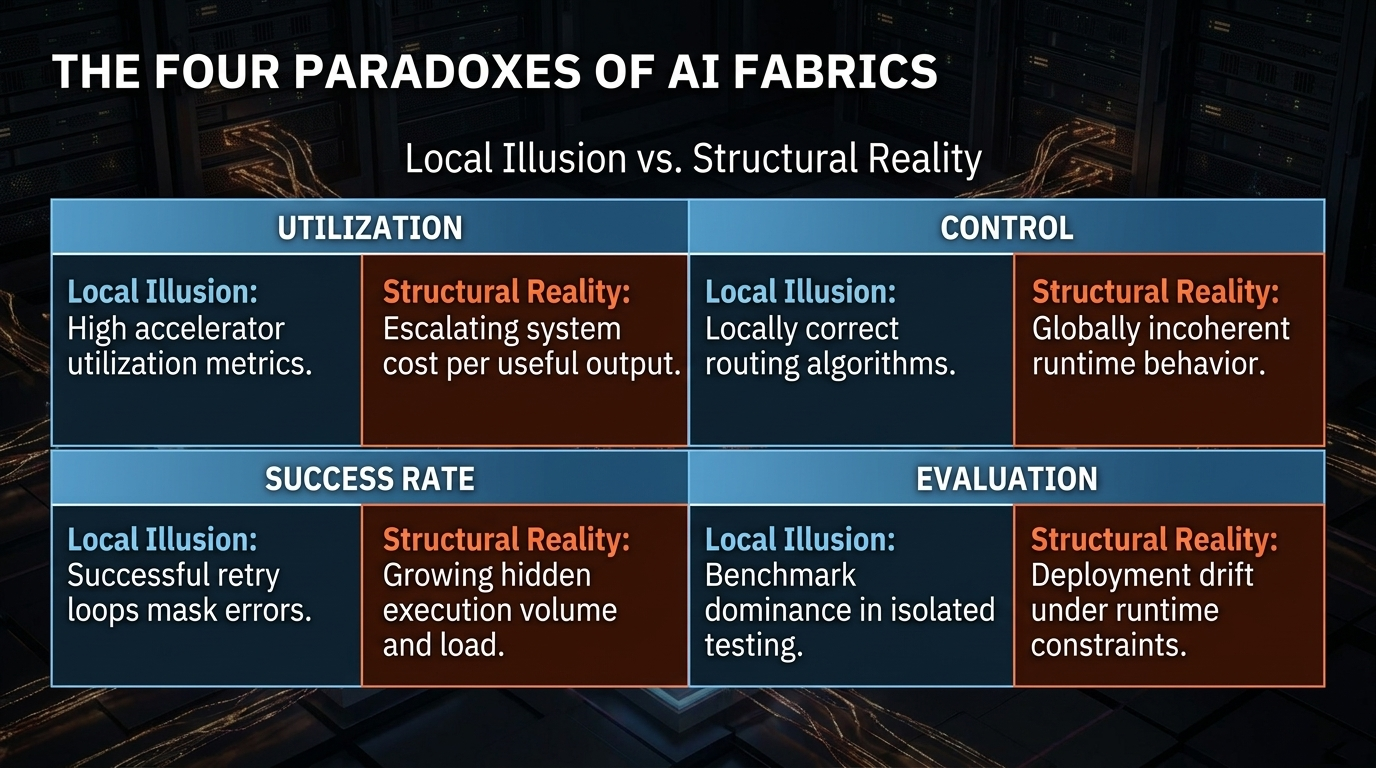
Standard diagnostics ask whether components operate within expected local parameters. SORT-AI asks a different question: whether the composed system remains structurally coherent when locally correct components interact across runtime, control, deployment, adaptation, and evidence surfaces.

Local correctness does not imply global coherence once execution is distributed across AI fabrics.