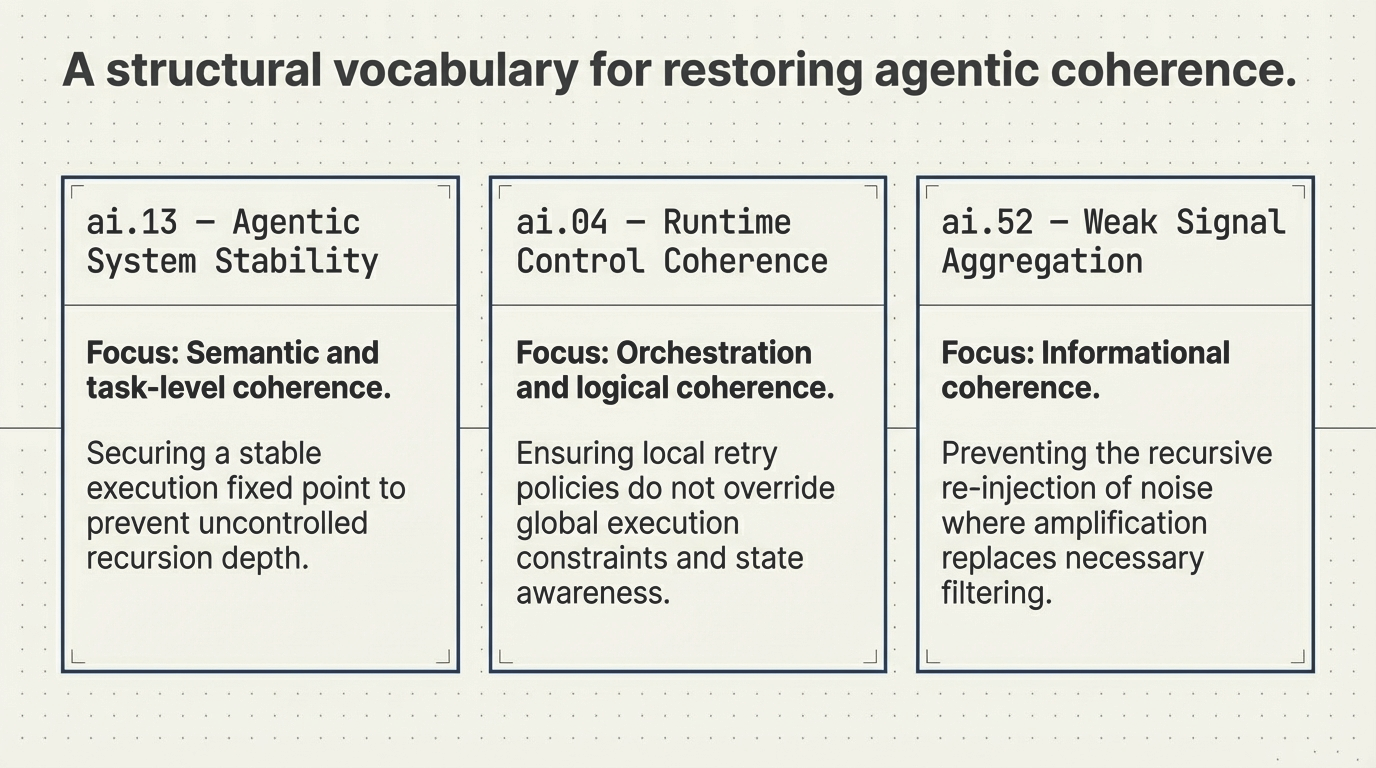
1. The Structural Gap
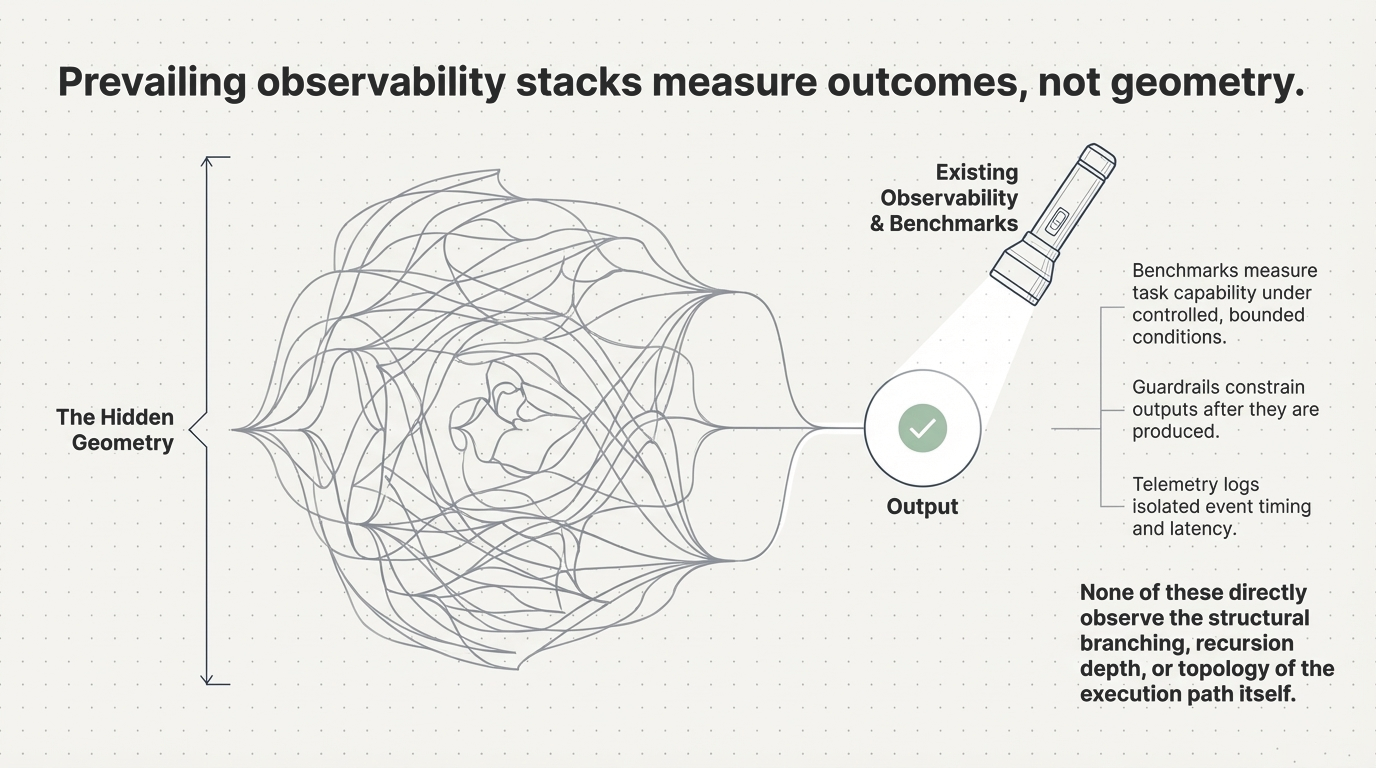
Benchmarks measure reasoning accuracy. Leaderboards compare architectures. Optimization efforts focus on latency, throughput, and cost per inference. Yet in large-scale deployments, something fundamentally different has become true.
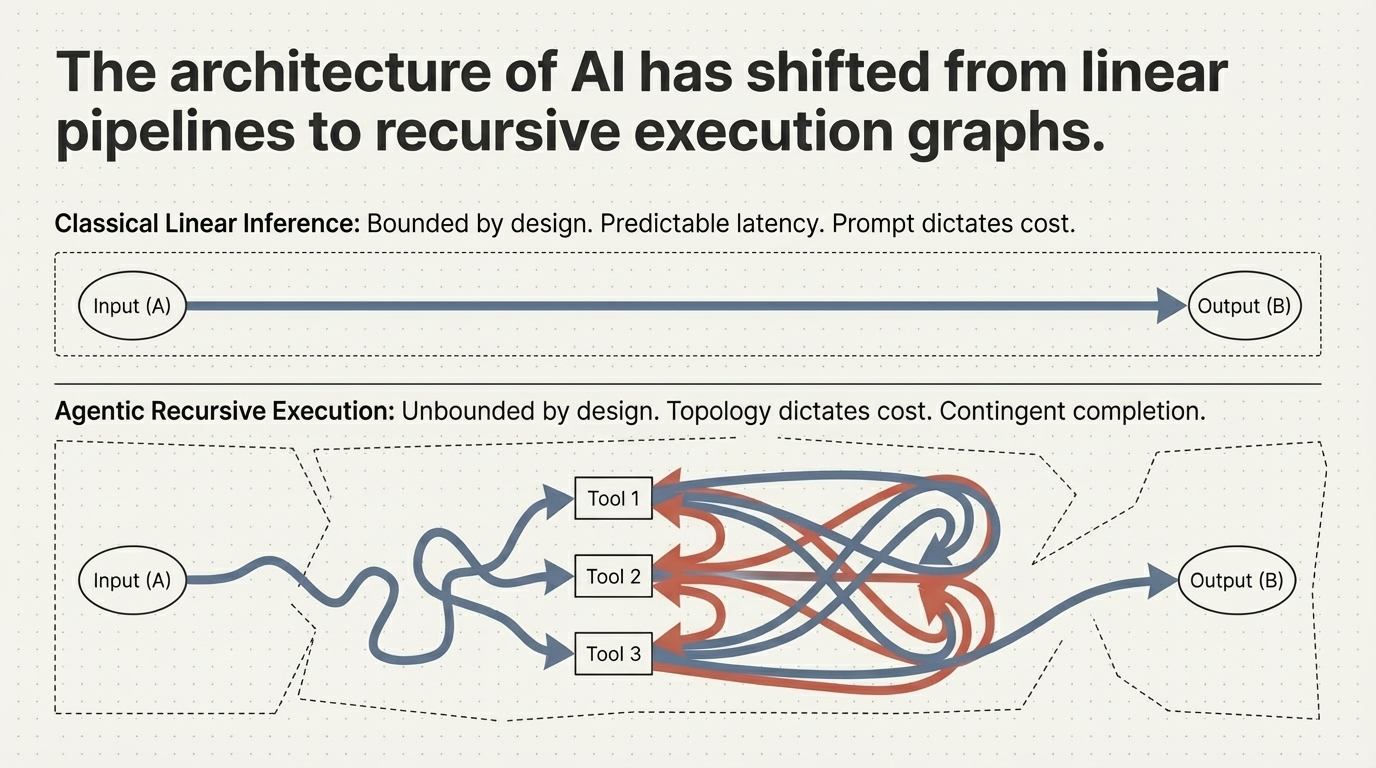
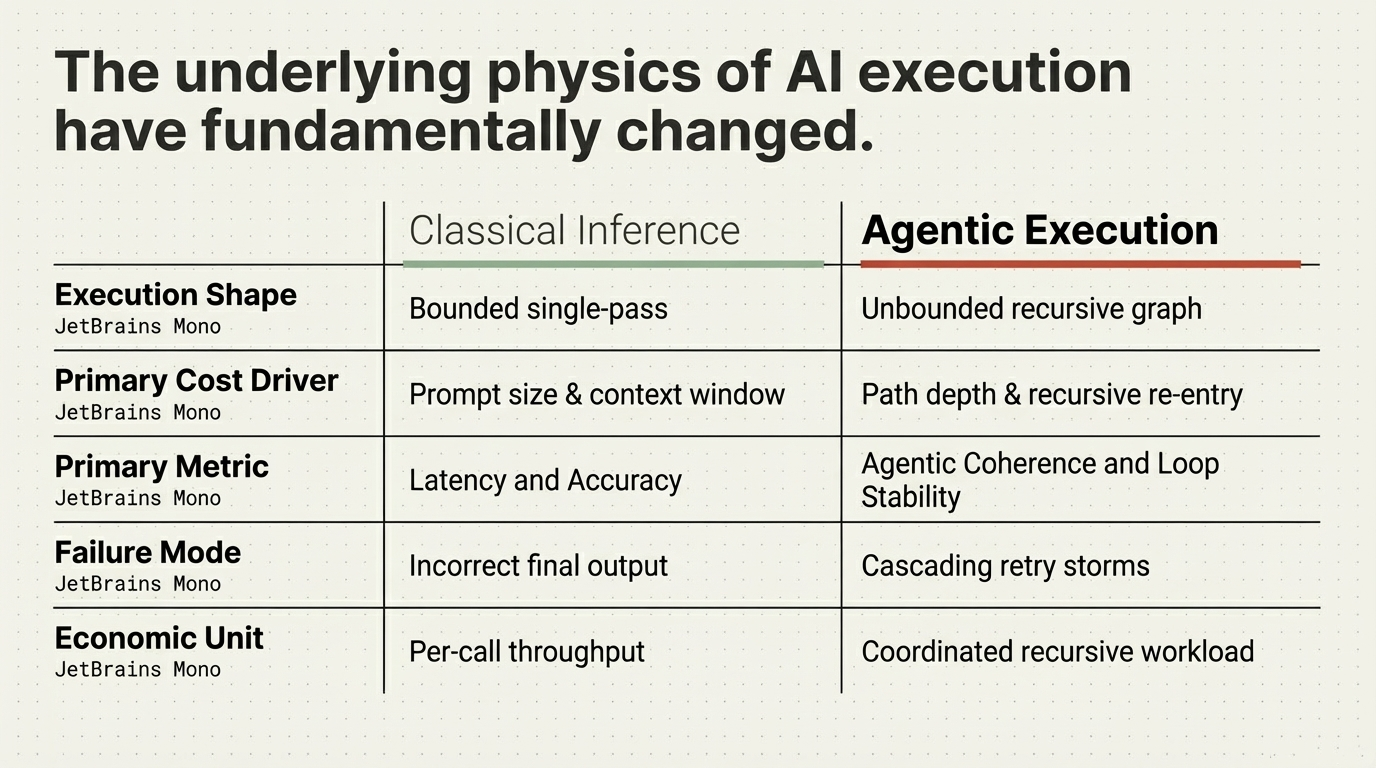
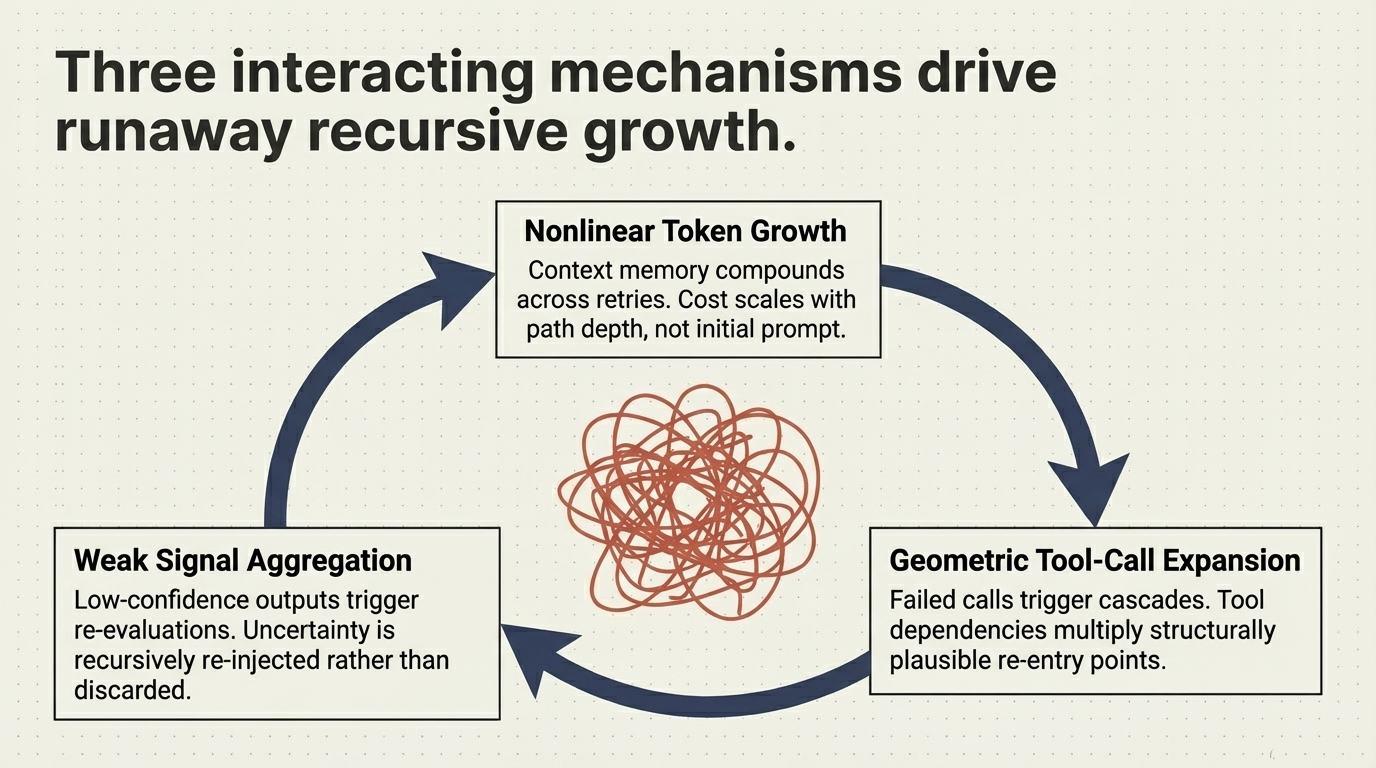
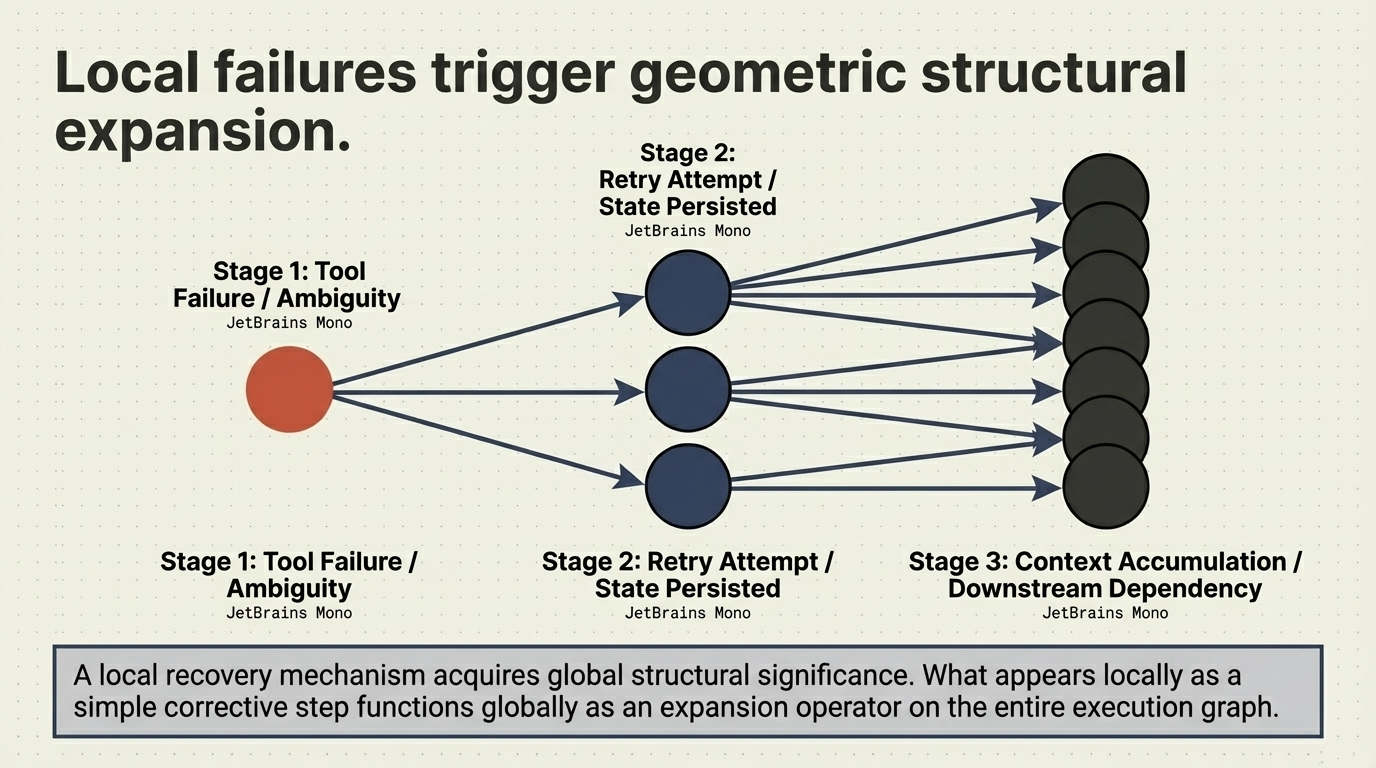
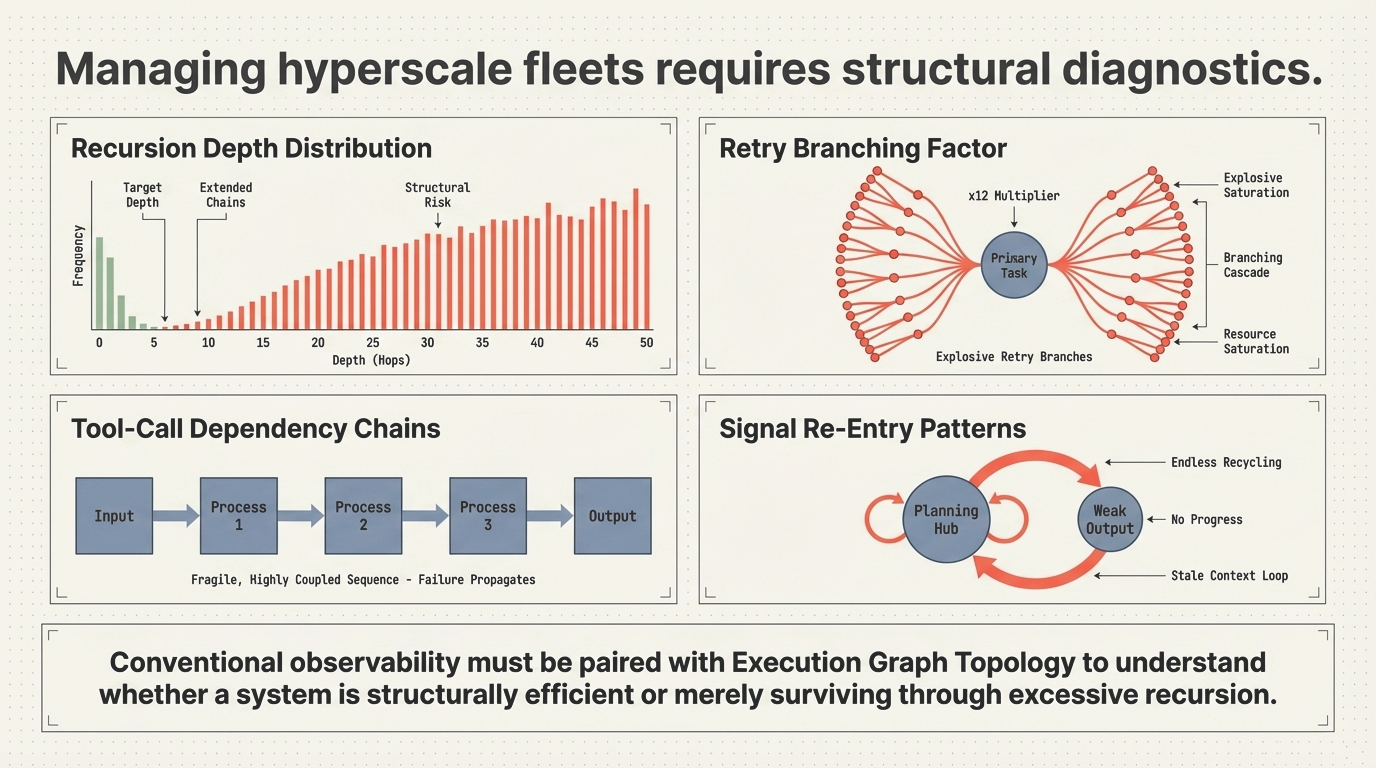
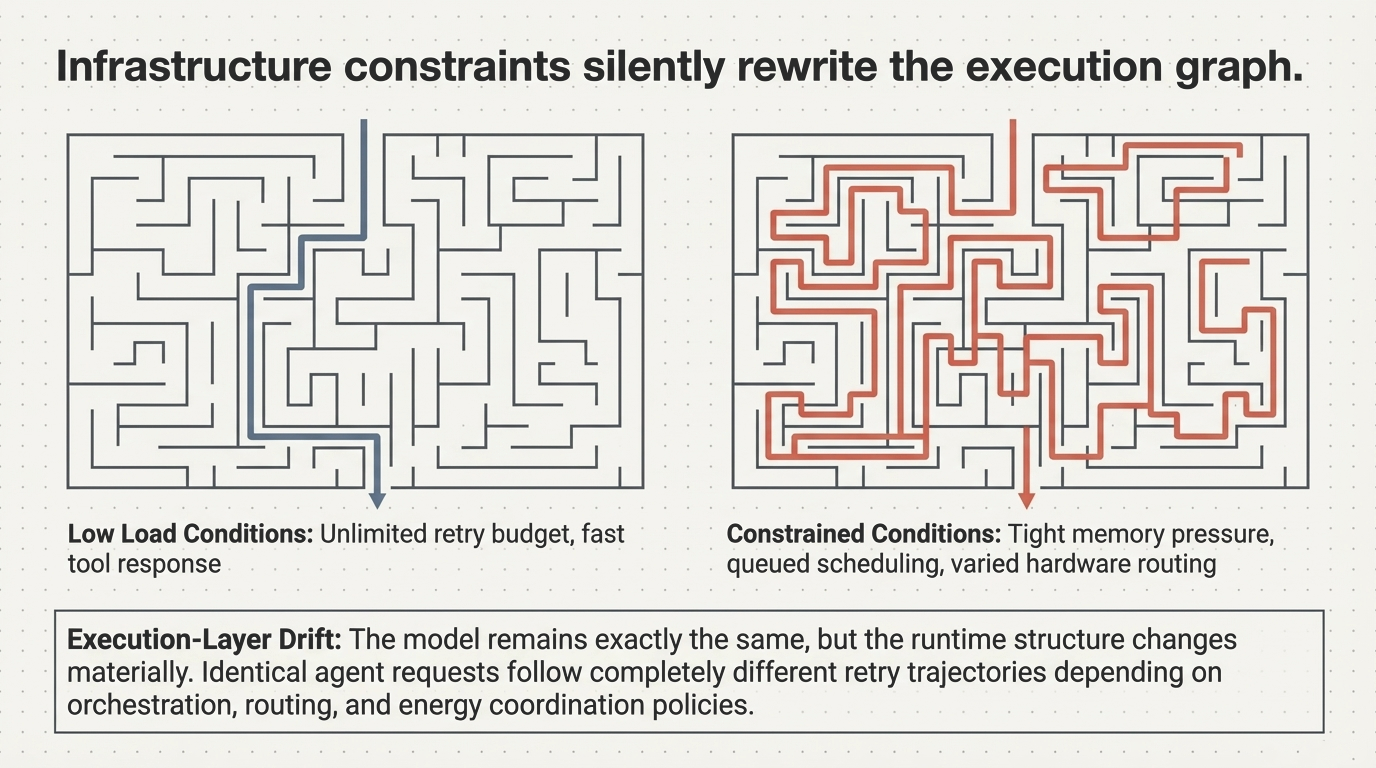
Many of the most significant performance, cost, and reliability characteristics of modern AI systems are no longer determined by the model itself. They are determined by how execution unfolds after the first inference call. In agentic systems, this means one thing in particular: recursive execution.
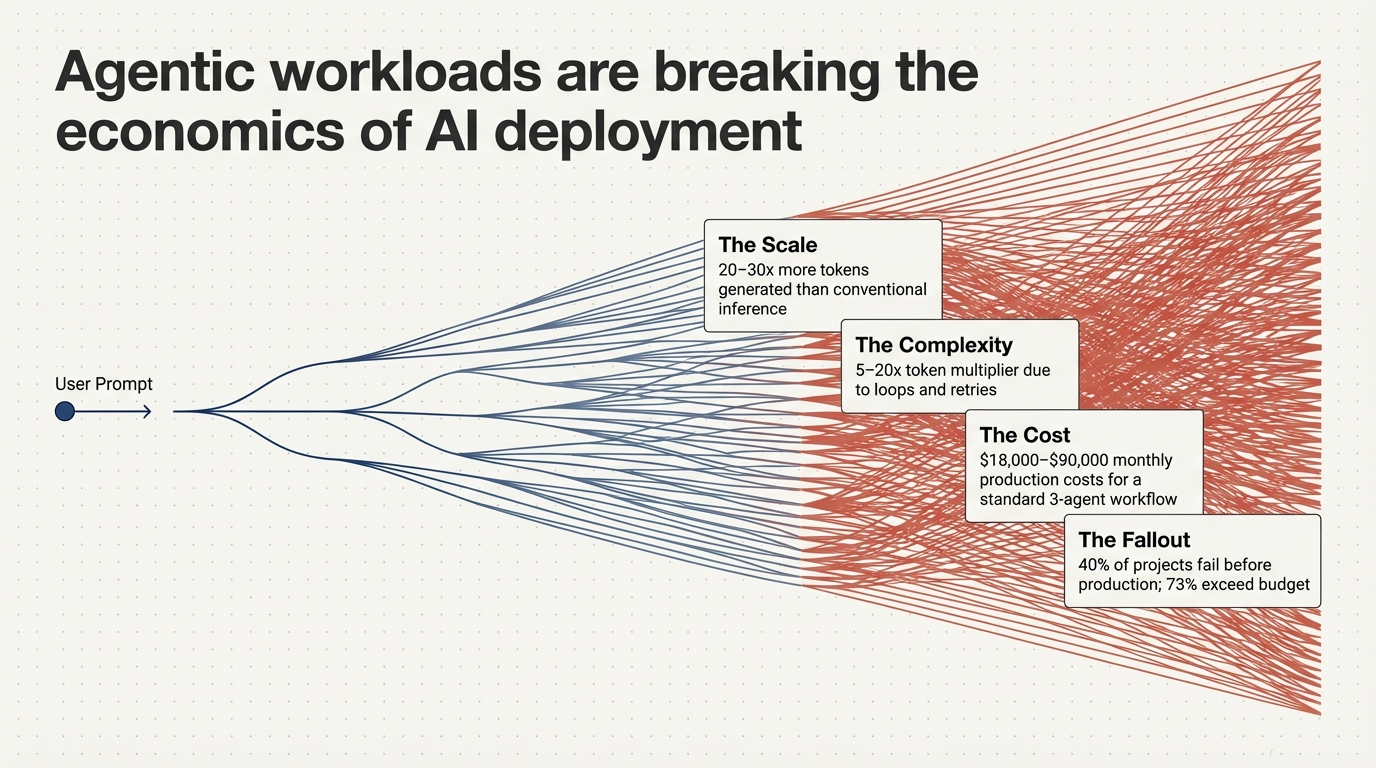
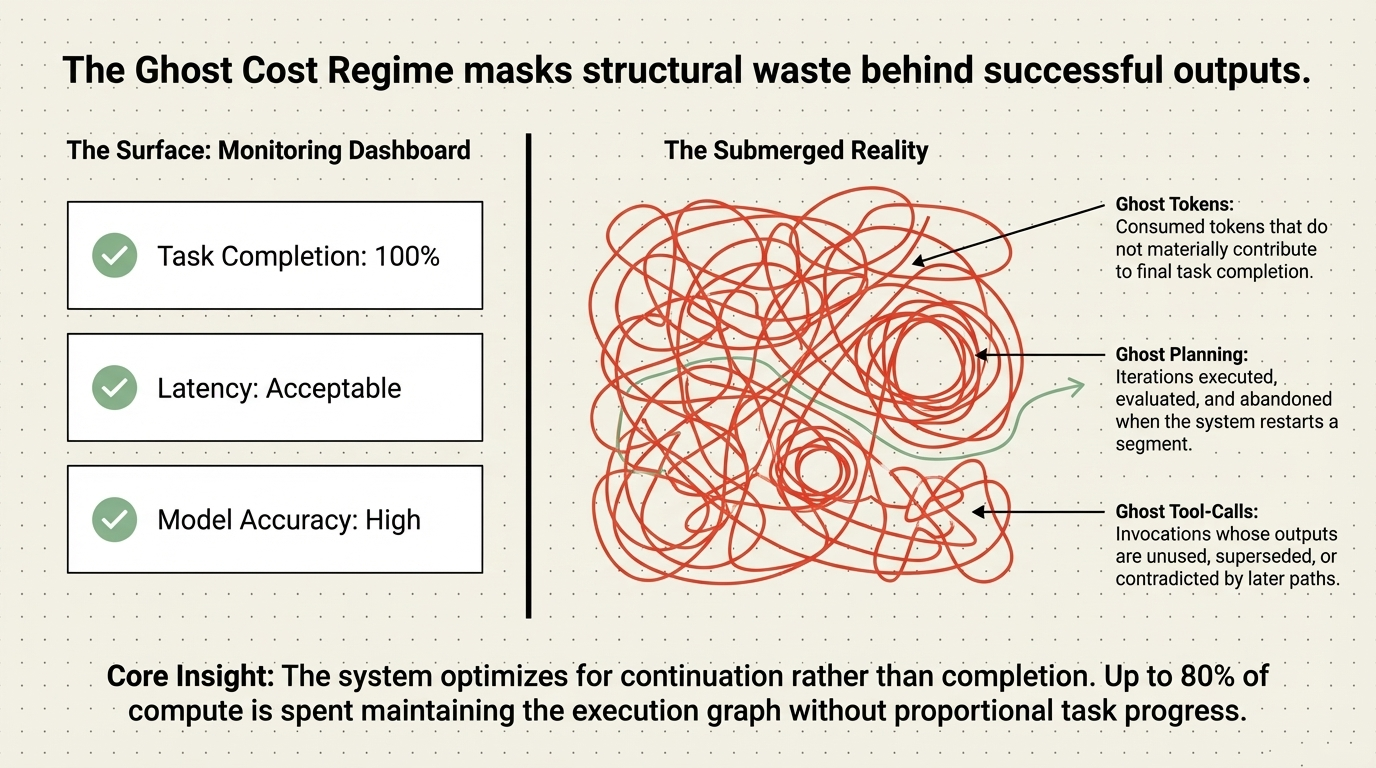
Figure 1: Agentic workloads are breaking the economics of AI deployment—20–30× more tokens, 5–20× token multiplier from loops, $18k–$90k monthly production costs for a standard 3-agent workflow, and 40% of projects failing before production.
This creates a structural gap. Systems that appear performant under benchmark conditions can exhibit unstable, inefficient, or economically unpredictable behavior in production—not because the model is insufficient, but because the execution structure is. An estimated 40% of agentic AI projects fail before reaching production, and 73% exceed budget. The root cause is not model capability. It is recursive execution topology.