1. Benchmark Saturation as a Structural Turning Point
Modern AI systems are typically compared through benchmark performance. Leaderboards rank models by task accuracy. Evaluation suites reduce complex behavior to comparable scores. Product teams, procurement teams, and platform operators often treat those results as the most objective basis for deployment choice.
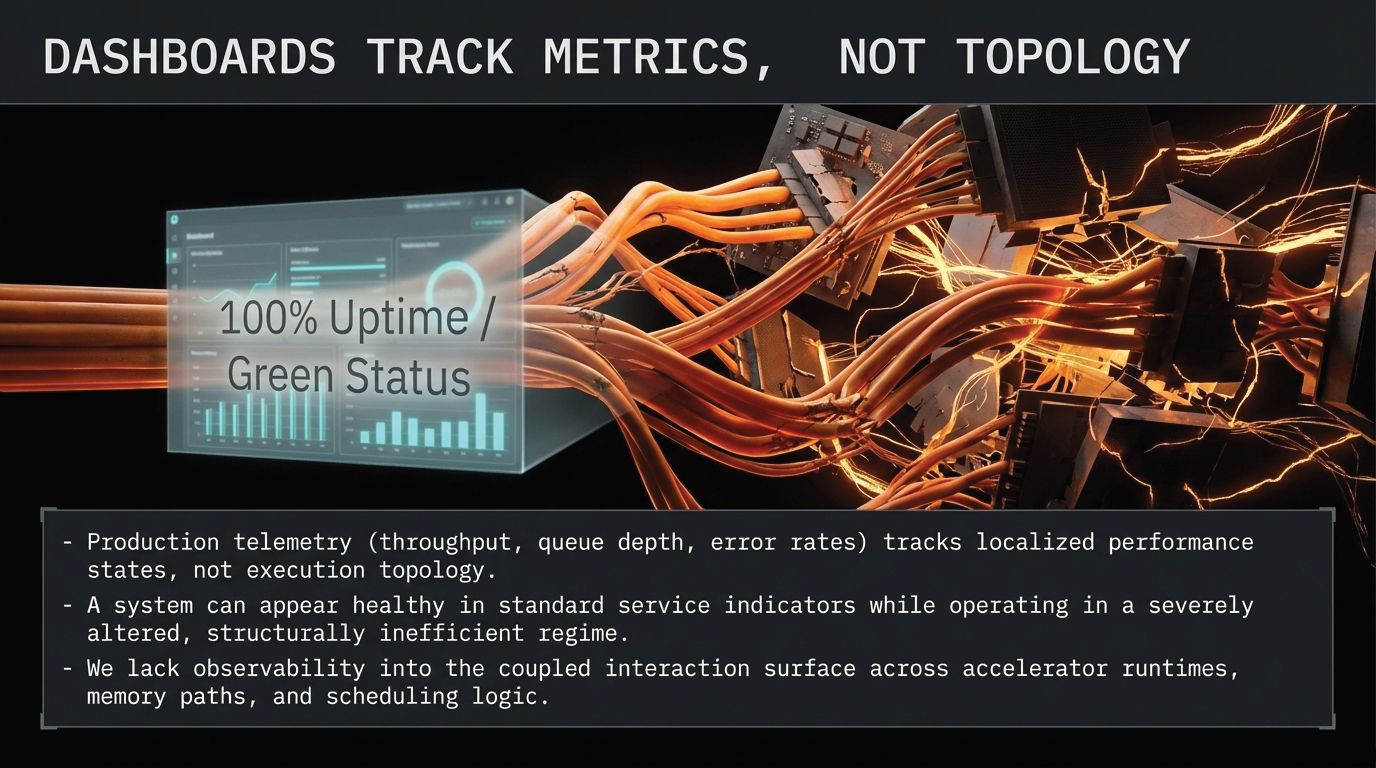
Yet in large-scale deployment, something different has become true. As frontier benchmark scores converge within increasingly narrow performance bands, the practical meaning of model comparison begins to change. Systems that appear nearly identical under controlled evaluation can behave very differently once they are embedded in real serving environments. What looks like marginal variation at the benchmark layer can become material divergence in production.
This is not an anomaly. It is a structural gap that is now emerging across large-scale AI systems. Benchmark saturation does not mean models have stopped improving. It means that benchmark superiority alone is becoming less decisive as a predictor of deployment behavior. As score differentials narrow, the critical variable begins to shift from measured capability in isolation to the execution conditions through which that capability is expressed.
This is the economic and methodological turning point that the industry is now navigating. For organizations selecting models primarily on the basis of saturated benchmark scores, the decision framework itself is losing resolution. The question is not whether benchmarks still matter—they do. The question is what else now matters, and where the explanatory power has shifted. As explored in the Projection Paradox, this gap between evaluation and production is a structural coupling problem, not a measurement problem.