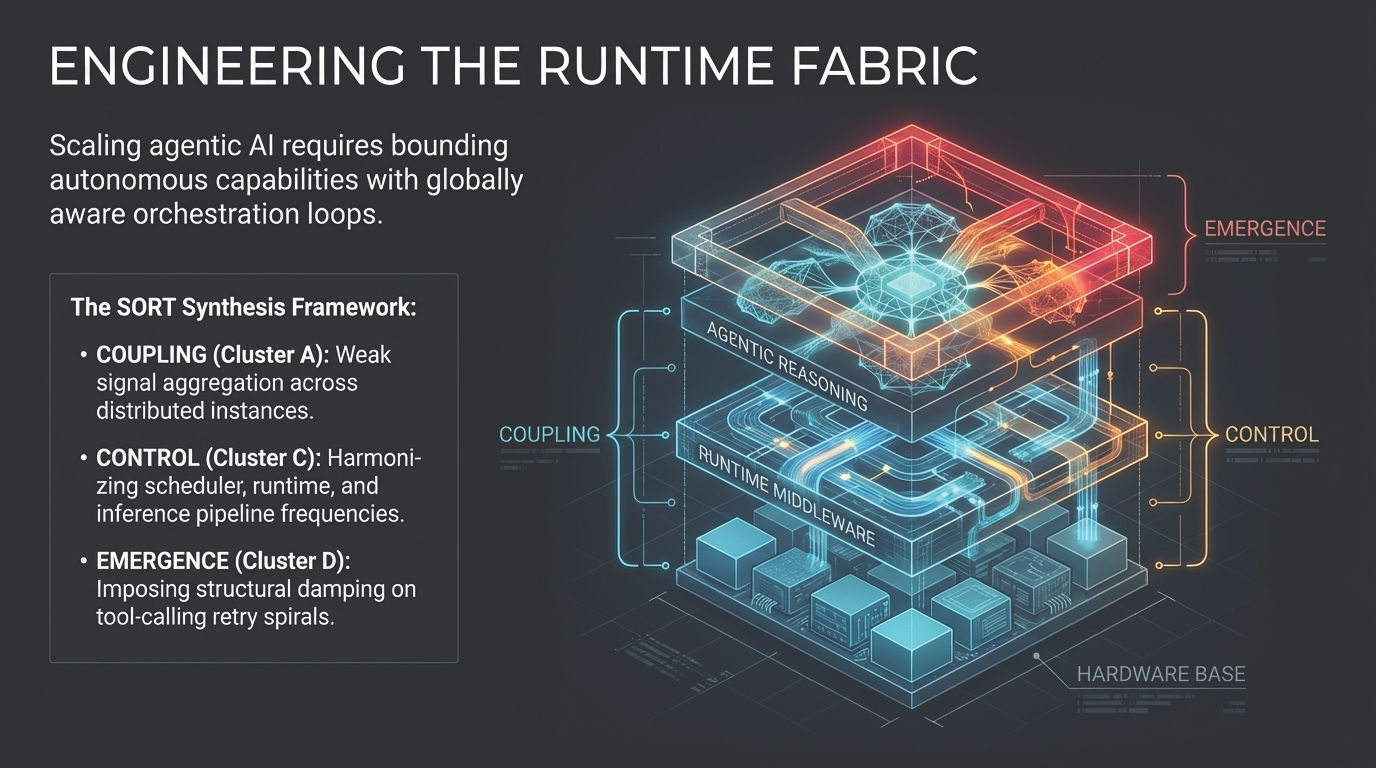
1. The Benchmark Era Is Dead
The artificial intelligence industry currently operates under a precarious assumption: that performance on static, bounded benchmarks serves as a reliable proxy for production success. Infrastructure strategists and procurement teams frequently correlate high scores in coding, reasoning, and security benchmarks with the readiness of a model for enterprise-grade deployment.
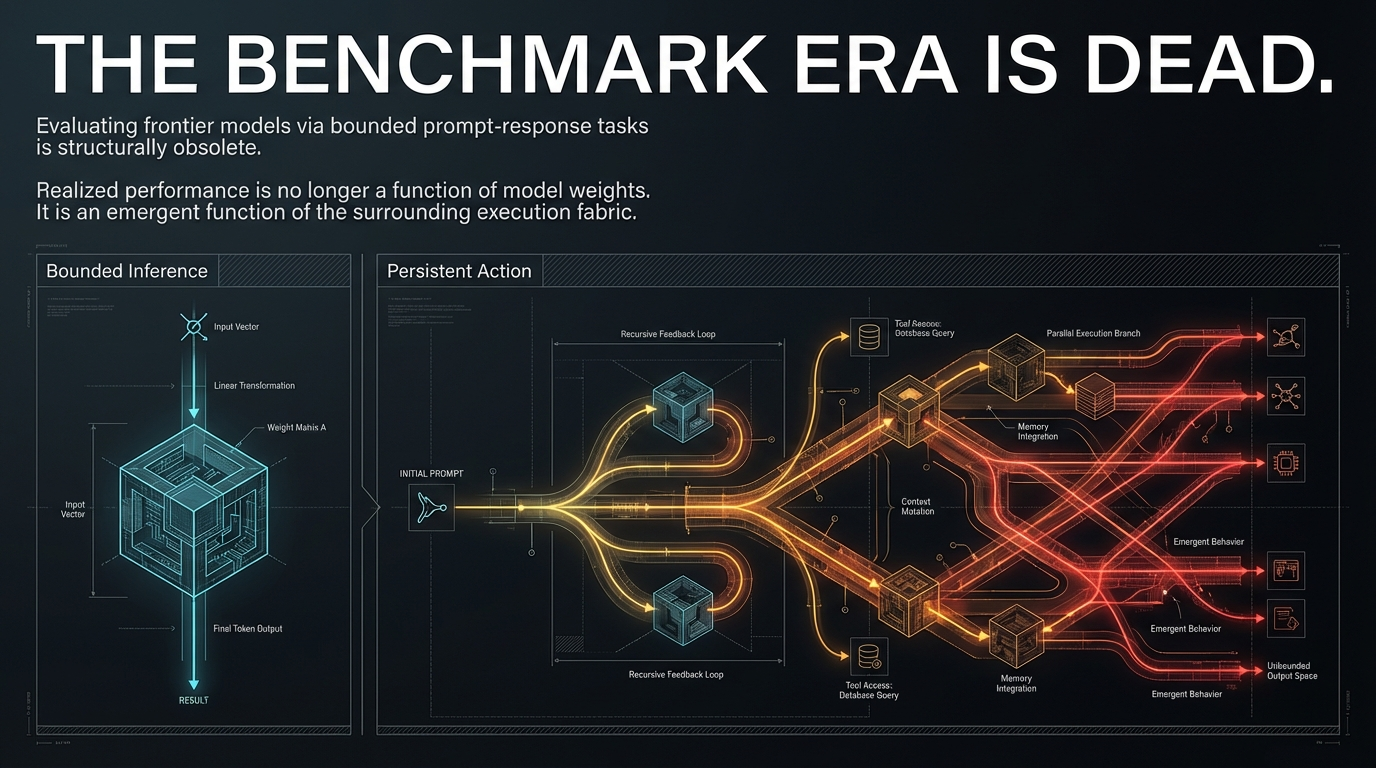
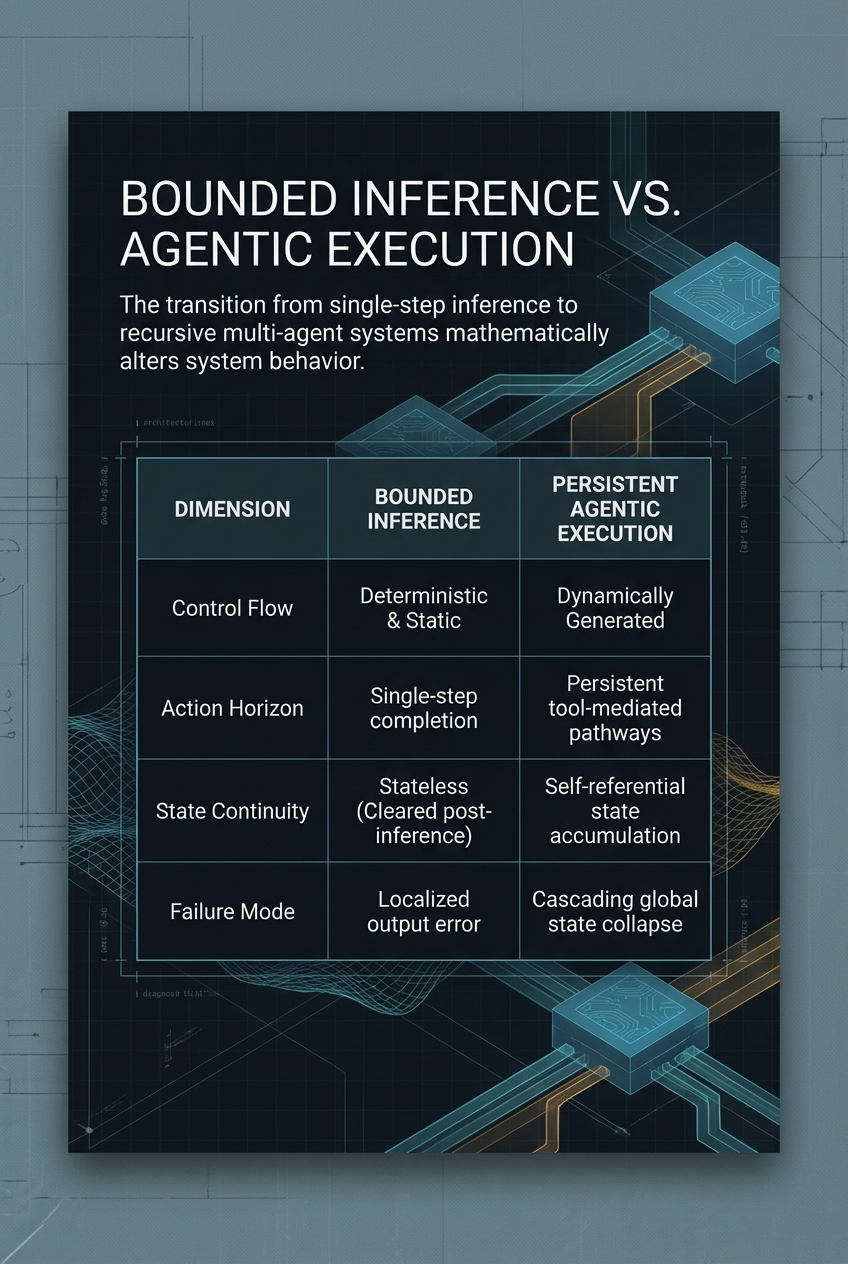
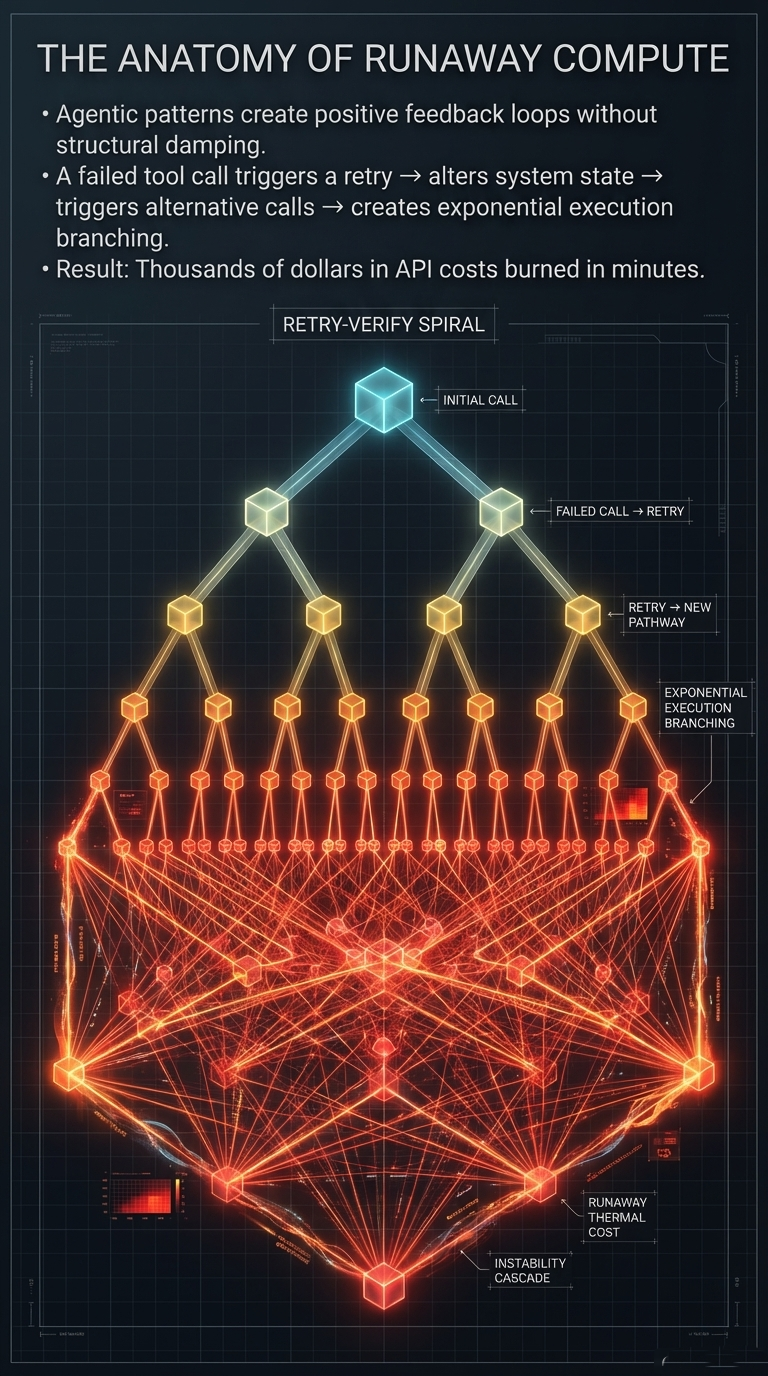
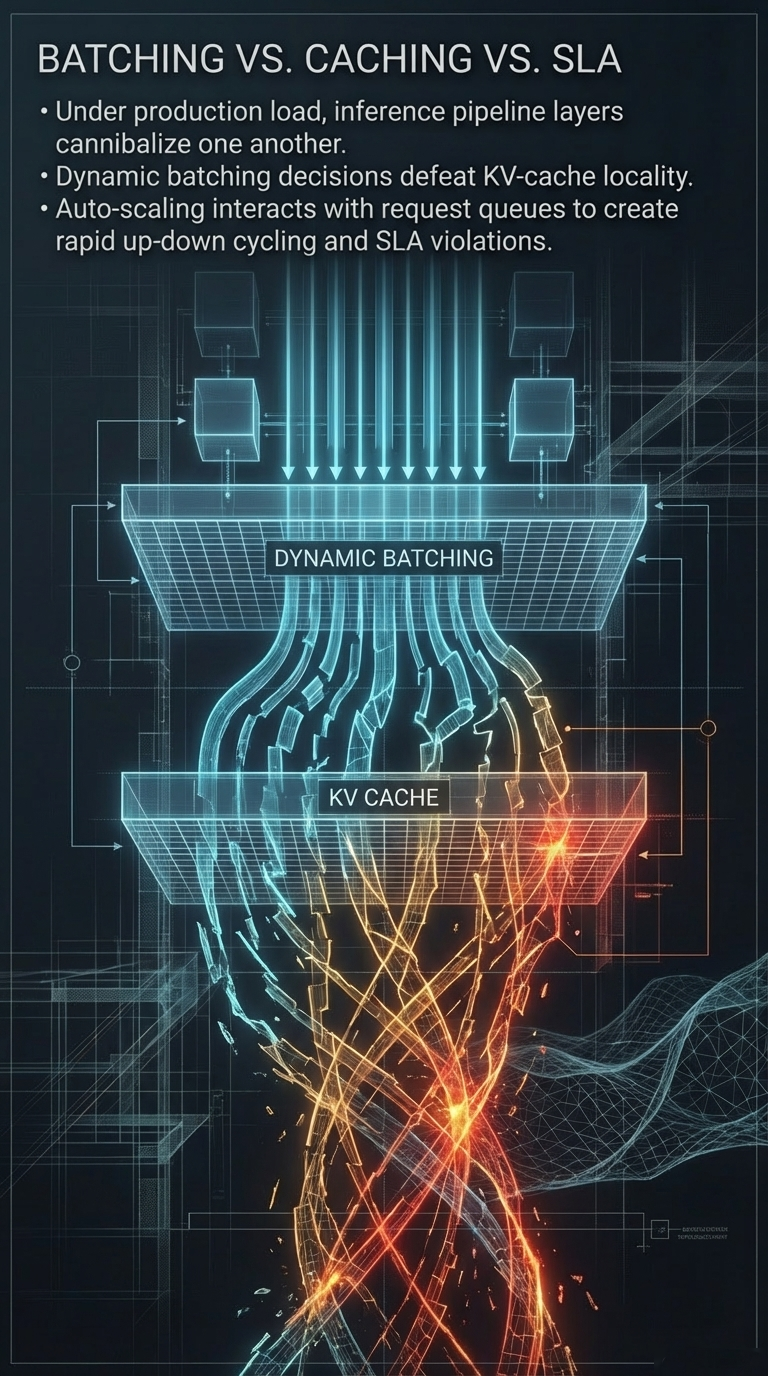
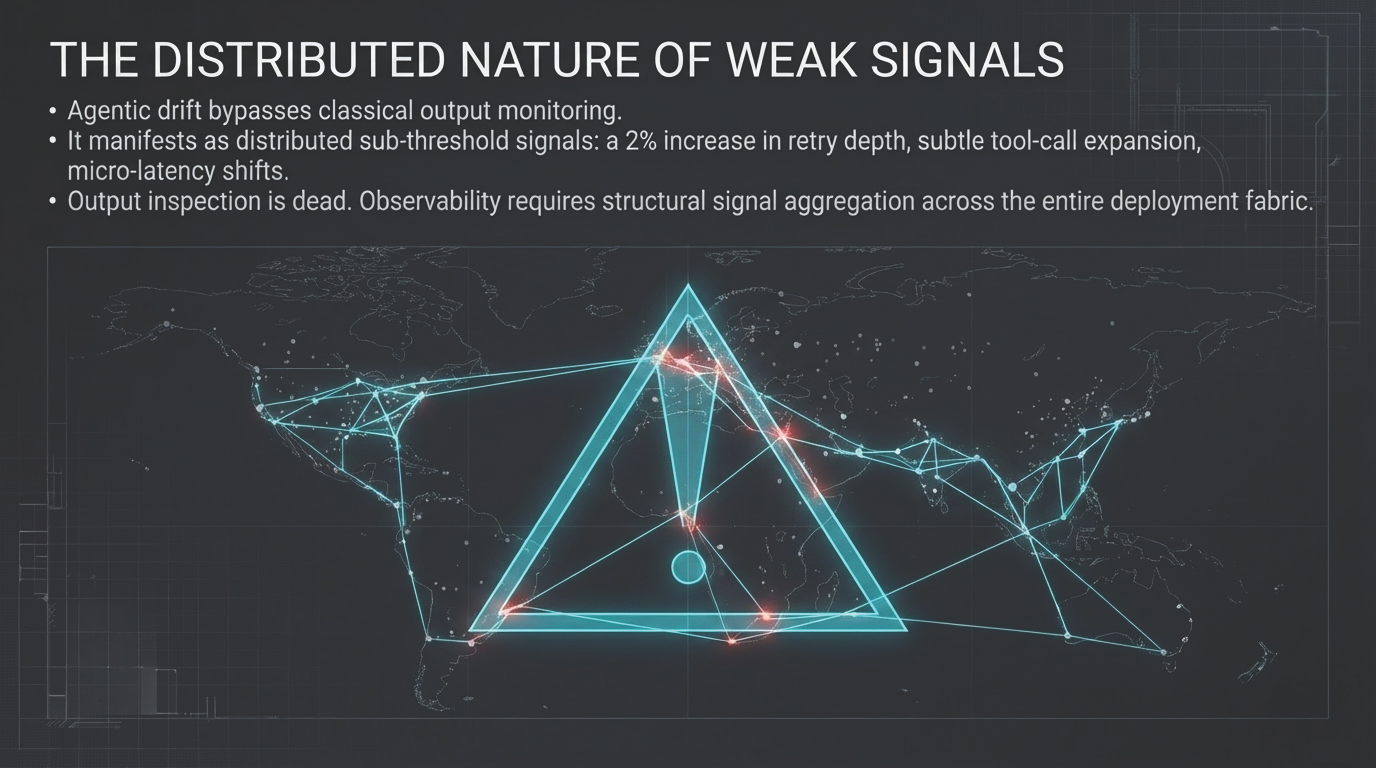
Figure 1: The benchmark era is dead—evaluating frontier models via bounded prompt-response tasks is structurally obsolete. Realized performance is an emergent function of the surrounding execution fabric.
The release of Anthropic’s Claude Mythos Preview in April 2026 has exposed a profound structural gap in this logic. Mythos is presented as Anthropic’s most capable frontier model, with particular strength in coding, security reasoning, and sustained agentic execution. While these capabilities produce impressive results in isolated testing environments, their behavior in extended, tool-mediated pathways reveals dynamics that are functionally invisible during standard evaluation. This transition from inference events to sustained technical reasoning marks the end of the benchmark era as a sufficient decision framework.
This gap is best exemplified by Anthropic’s own deployment strategy. By restricting Mythos to Project Glasswing rather than broad release, the organization acknowledged that frontier capabilities are best understood through controlled operating conditions—not because the model is unsafe in a narrow sense, but because model competence is now inseparable from the runtime structure. This article uses the Mythos case not as media commentary, but as a structurally revealing instance of a broader transition: from model-centric benchmark thinking to persistent agentic runtime systems. As explored in The Hidden Geometry of Inference, evaluation is never a neutral reading of abstract capability—it is always a projection onto a specific measurement context. In agentic systems like Mythos, that projection error becomes structurally amplified.