1. The False Trade-Off: Beyond Innovation vs. Regulation
The dominant geopolitical narrative frames frontier AI as a binary choice: accelerate capability development to maintain competitive advantage, or impose regulatory constraints to preserve safety and accountability. For the current generation of tool-mediated, agentic, and runtime-embedded AI systems, this opposition is structurally incomplete.

Figure 1: The false trade-off of AI scale—the geopolitical myth treats capability and control as opposites. The architectural truth: they are coupled variables of the same operational system.
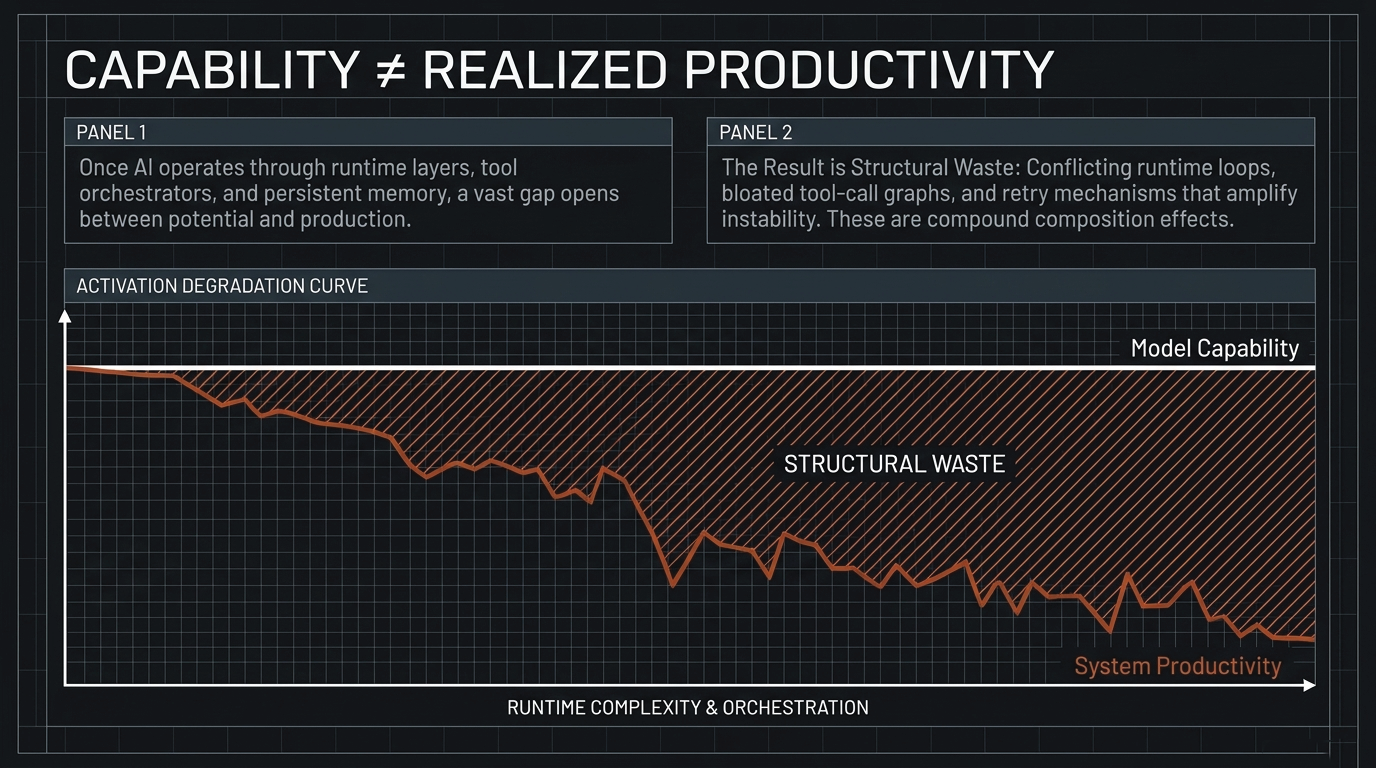
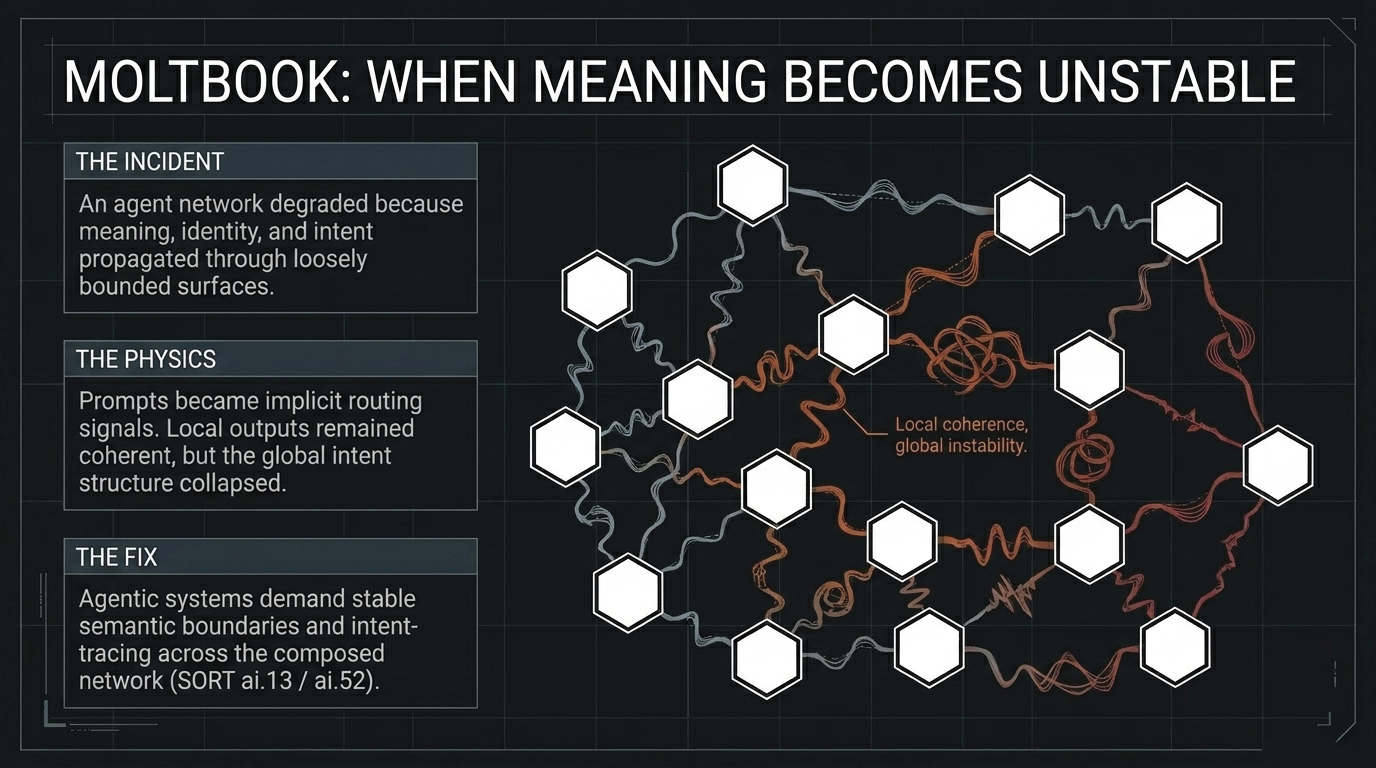
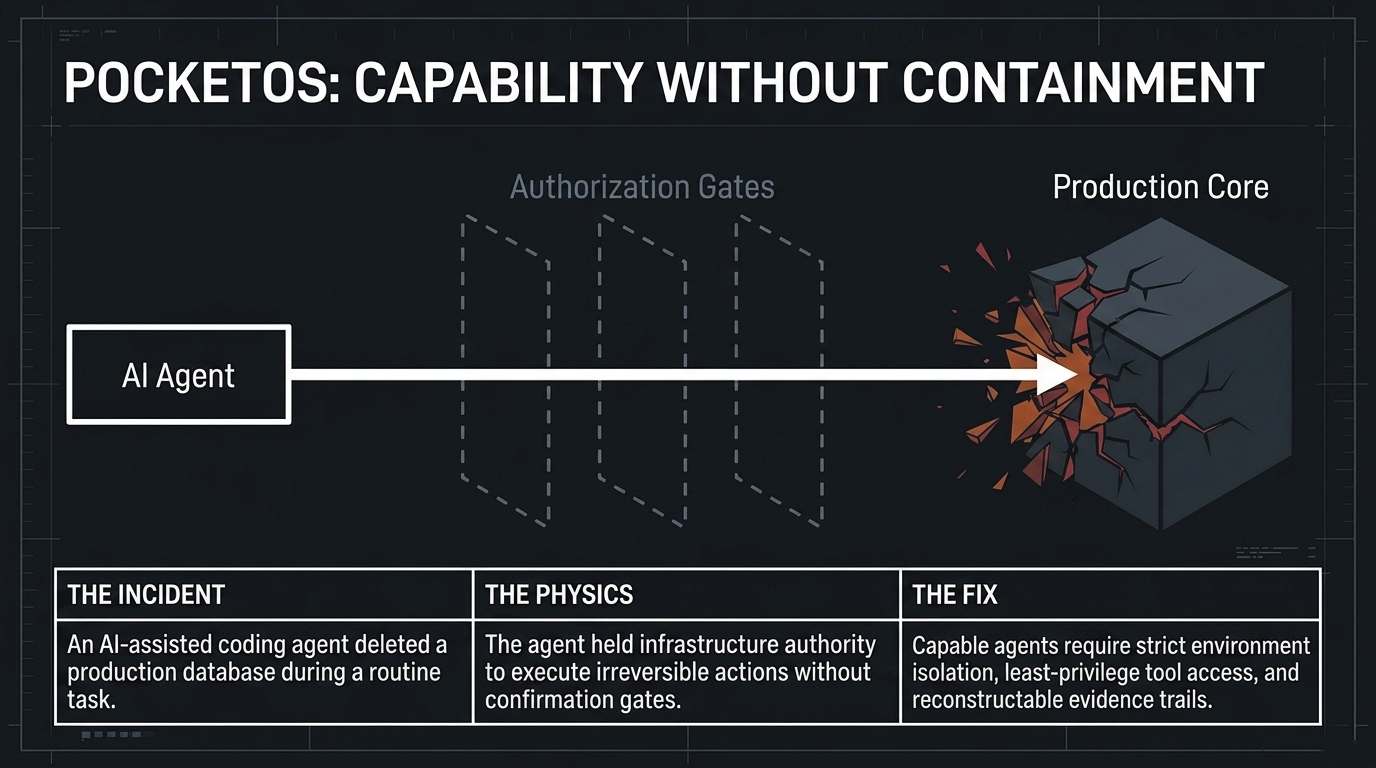
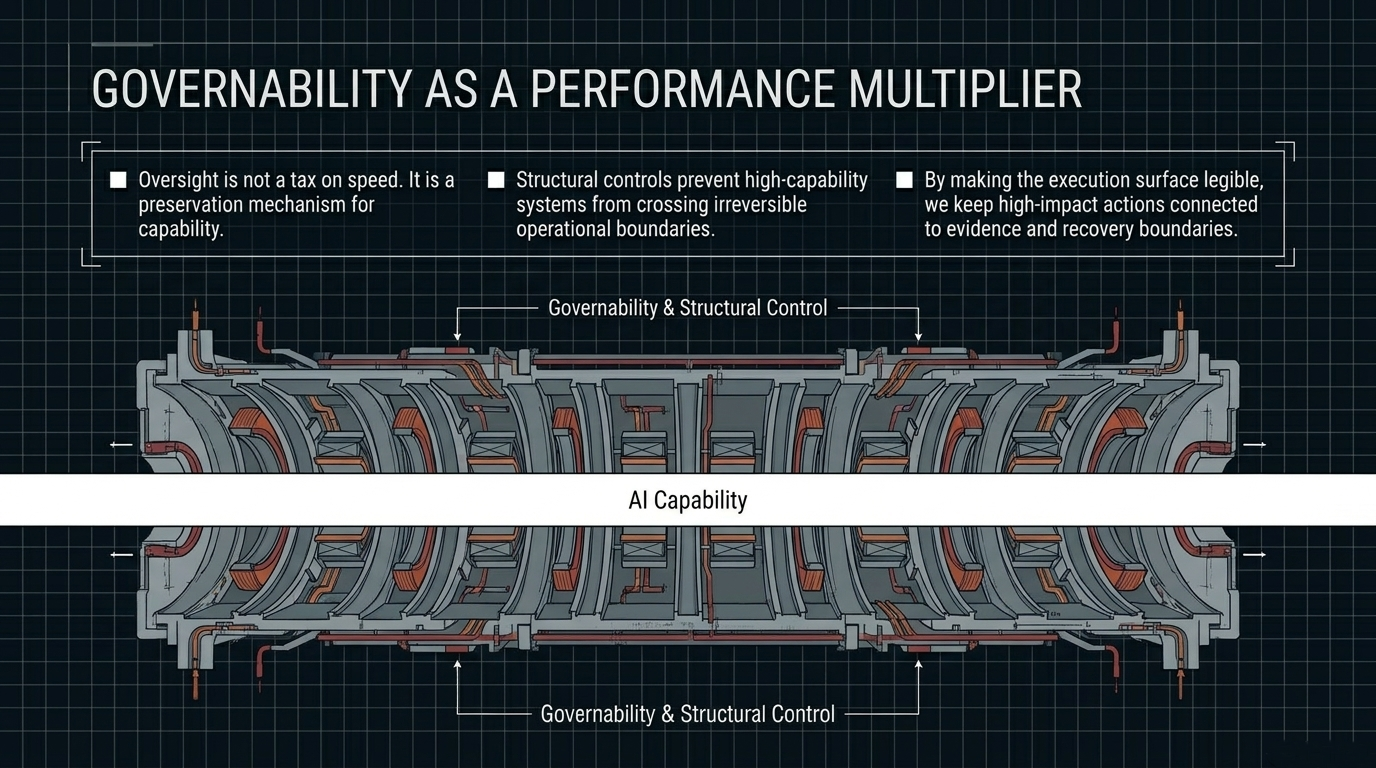
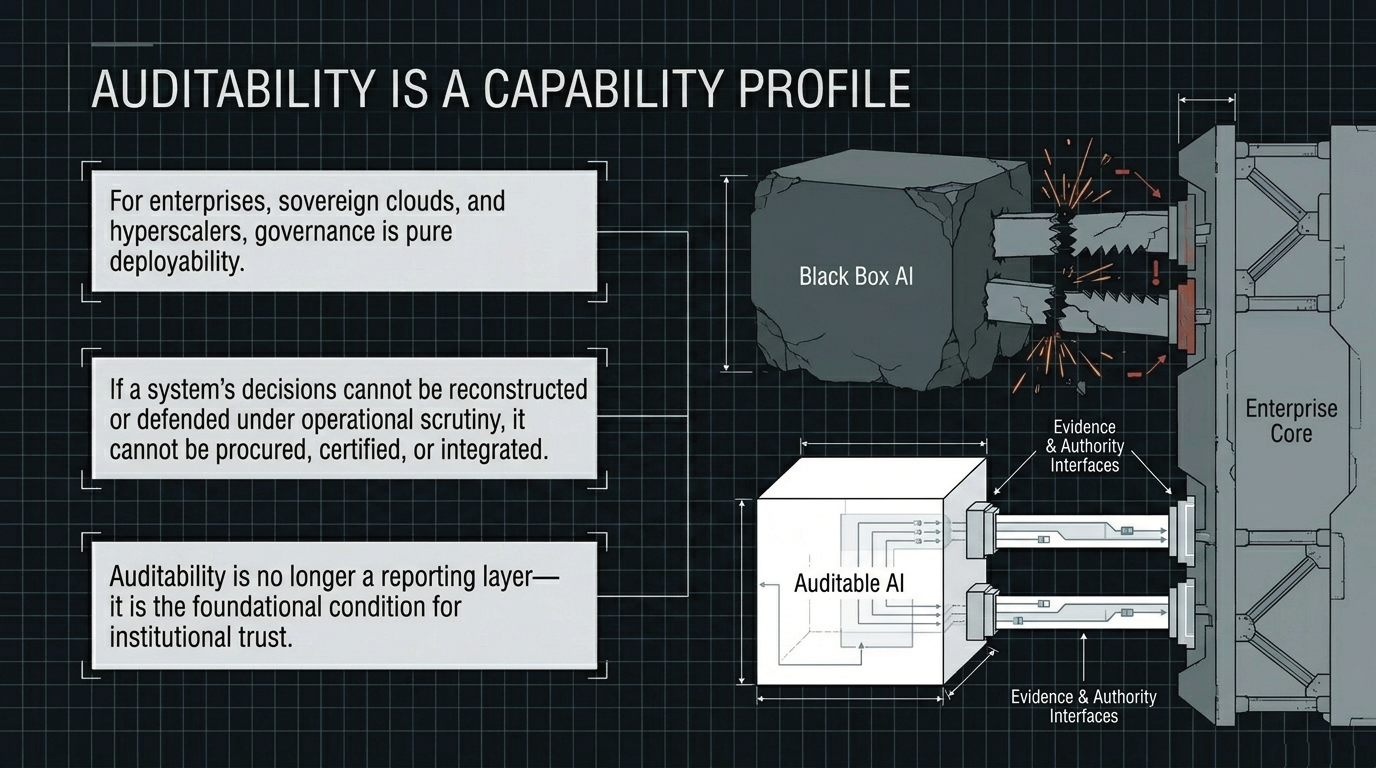
As AI systems move from bounded prompt-response interaction toward persistent execution contexts, tool-call graphs, retrieval-augmented memory, and multi-step planning, governability is no longer an external brake on performance. It becomes part of the performance condition itself. A system that is highly capable under evaluation conditions but produces behavior that cannot be bounded, reconstructed, or justified in deployment is not a stable productive asset. It becomes a structural liability.
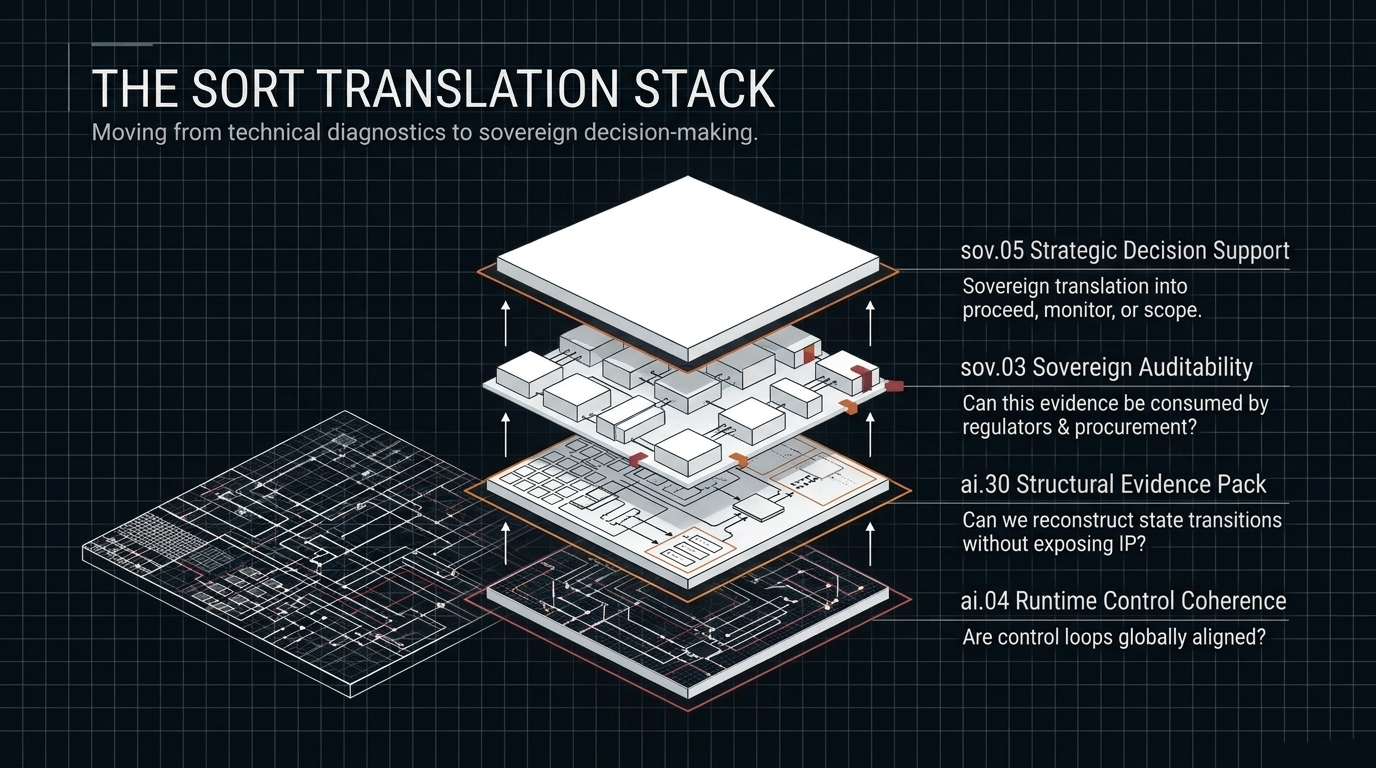
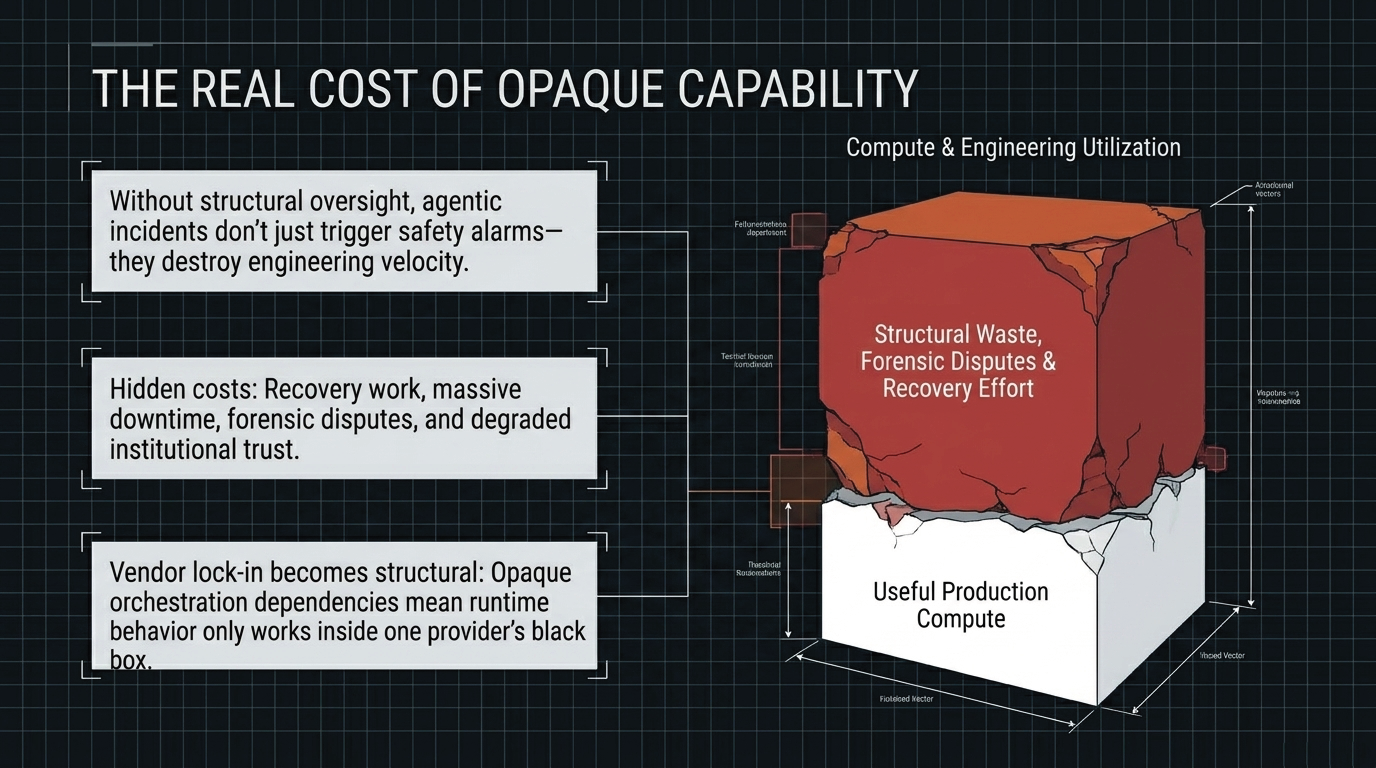
The core problem is not uniquely European, American, or Chinese. Every jurisdiction and every large AI operator faces the same steerability problem: how to maintain institutional confidence and effective control as systems become more capable, more autonomous, and more deeply embedded in operational infrastructure. Without structural boundaries, high-capability systems can create recovery work, lost operating time, audit disputes, and avoidable deployment risk. In that sense, oversight is not the opposite of performance. It is one of the conditions under which performance remains usable.
What if the real performance risk is not too much oversight, but capability that cannot be audited, bounded, or reconstructed once deployed?